How to migrate from IBM Rational Synergy to Git

No one stays in IBM Rational Synergy voluntarily, but migrating is a scary task. We have some experiences that can help you plan your migration.
The history of IBM Rational Synergy
IBM Rational Synergy is a client-server based version control system that has evolved from a single file version control system in the 90’s to a task management system topped with a change management system called Change. It has been branded under different names (Continuus, CM/Synergy and most recently Rational® Synergy) over the years and under different companies ending at IBM® under the Rational® brand.
In the 2000’s it had a few strengths which gave it traction in the market. Firstly, it is a task-based configuration management system which is a step up from systems like CVS. In Synergy, you can assign tasks to developers that change and add file revisions and finally complete the task for a particular release.
Secondly, it has the concept of repositories which are great for larger organizations - many teams delivering components to product lines.
Thirdly, it could be extended with Rational Change to implement software change management processes, customized hierarchies, properties and life-cycles.
IBM Rational Synergy is close to its end of life
The tool is maintained, but has had no feature updates for many years, so it is close to its end-of-life. Due to this singularly critical reason it should be on the IT agenda to migrate quickly to a new system like Git.
Beyond that, as a system, it is very slow to use, requires a lot of manual work to do trivial merges, is designed for long-living release branches and is complex to understand. All of this can kill development teams’ efficiency.
My experience is that teams and organizations develop a mindset of “don’t touch it”. This means they do not even develop or optimize their use of Synergy to meet the needs of the teams. They all live with it and work around it. This alone indicates that it is time to move on.
The big question is: can it be done? The short answer is “in all likelihood”. It really depends on the way Synergy has been used over the years.

Planning the migration
Matching Synergy and Git data models
Synergy has a very loose model for how software changes build up a revision. This presents challenges in migrating from Synergy to Git. The data models are completely different. These are the major differences.
.png?width=662&name=migration-to-git-graph1%20(1).png)
Mapping concepts overview
Based on the migration experiences, we have developed a migration strategy summarized in the table below with a quick verdict followed by detailed reasoning.
|
Synergy |
Git |
|
Files and history |
Not directly |
|
Tasks |
Not directly |
|
Baselines |
Not directly |
|
Releases |
No |
|
Projects and revisions |
Repository, commits and tags |
|
Subprojects |
Submodules |
|
Custom attributes |
No |
Files and their history - not migrated directly
Files in Synergy have their own history of revisions and they could be interesting to migrate, but file revisions does not exist in Git as a revision itself.
Synergy File objects have types and based on those the file can have different newlines, viewer and merge behaviors. To a large extent this can be implemented in .gitattributes. One thing which remains to be handled explicitly is execute bits as they are not automatically set in Git.
Be aware of existing .gitignores and .gitattributes of imported source code as they can cause unintended behaviour when present during migration.
Merges are carried out on a file object level.
Tasks - not migrated directly
Tasks would be the ideal object to migrate as it is a single change similar to a patch file in Git. This means that it does not have a parent relation. They will not be migrated, but they will be listed in commit messages and annotated tags.
Baselines - not migrated directly
Baselines, also called baseline objects, cannot be migrated as such, because it is just a meta-data container and a link to project revisions, tasks and Change Objects. The closest we get in Git is annotated tags and the baseline information is added as the annotation. Baselines are a relatively new concept and only became mandatory in version 7.x, so it is not a reliable source for migration.
Releases - not migrated
Releases are somewhat the same as branches, but they are usually used as long living release branches.They will only appear in the naming of the annotated tag.
Projects and Project revisions - migrated
Projects and Project revisions in a static state is the closest we get to a commit in Git. The static states of projects revisions are: integrate, test, sqa and released. This is a reproducible revision which is based on a previous revision, called a project baseline. The project revisions are the best migration object as it contains the revision of the source code and has the history relationship.
A Synergy project should by default be mapped to a Git repository.
The revision name is usually the same as the release, build number or an ID the software organization can identify again later. Revision names or IDs are mapped to Git tags. After the migration, you will be able to find the equivalent software revision in Git with the same naming as you would in Synergy.
Project names and revisions have far less restrictions than Git naming of repositories and tags. It means that you likely must replace spaces and odd characters with dashes or underscores and likely also need to unify project names to lowercase.
In Synergy, multiple projects can have the same name, handled by the instance attribute. How we migrate these should be guided by the reason why duplicated project names exist. It could be that there is a different project in the repository manager or the history of all instances has the same target Git repository.
There is no concept of merges on a project revision level as a project revision can only have one parent.
In case the project revisions does not represent the revisions, builds or releases or they don't exist at all – does this disqualify a migration?
No, not necessarily. Usually, software organizations have release notes or bill-of-materials. They state baseline revision, subproject revisions and task lists. In this case it is possible to replay the revision and migrate it to Git.
Subprojects - migrated
They can be directly mapped to submodules in Git, as the data model is the same. A project can have another project added as a subproject in specific revision. It results in a directory in the workspace. It is the same in Git.
Custom attributes - not migrated
They can be created on any object in the Synergy database. It gives special meaning to the development process which can be hard to redo in Git. It is not so much related to the migration itself, but how the development process adapted to working in Git.
The above should show that while you may lack a one to one mapping from Synergy to Git, you can make reasonable choices that allow us to migrate.
How to migrate
Since projects and their revisions are the unit for migration, let us dig a bit deeper into how to do the migration.
Projects
Firstly, you need to figure out which projects from which databases you would like to migrate. You might already have a sense of what to migrate, but I recommend querying the databases for projects in order to avoid missing some.
The databases might have been around for longer than the people working in the teams currently. You need to assess the projects to determine if they are targeted for migration or can be skipped. Some projects have subprojects and you must determine how to migrate those. It should either be preserved as a submodule or it should be a subdirectory.
File revisions impact
Working in a client-server SCM has usually given patterns of storing artifacts, dependencies and tools in the source. It does not fit well with a distributed source control system like Git as you carry, by default, the whole history of commits and files with you.
The size of the repository itself, but also the increase in size per revision, gives the first indication if the repository is sustainable in the long run. Actions to remediate this can vary from removing files, adding to artifact manager, adding to Git Large Files System (LFS) or submodules. It is hard to say up front which solution is best for each file or area. That evaluation and actions should be decided within the organization.
Metadata – Files, tasks and baselines
As mentioned above, the files, tasks and baselines cannot be migrated to Git as such, but they contain a lot of relevant information. The baseline object contains this information and it can be added to an annotated tag along with the commit message, which is great, as these are searchable via Git, but also parsable by Git repository managers. It will give you a traceability bridge from Synergy to Git.
You can migrate the Synergy tasks and Rational Change problems to your task management tool. The tasks can include information about the assignee, the release, a description and file lists.
Usually, repository managers and task management systems have integrations, so you can reference tasks in commit messages. It is then possible to use this method to link together the project revisions migrated and tasks in the task management system. It will give great traceability to the historic revisions. I’ve done a migration targeting BitBucket and Jira in the past. Synergy tasks were migrated to Jira as stories along with FixVersions and components.
Iterations and verification
Experience over the years tells me that you will have to tune the migration machinery a few times to get it right. It is an iterative process. There are decisions that need to be made, which is related to processes and structure. In all likelihood you are changing the engine of the car while you are driving, so you should expect to rehearse the migration several times.
The migration should be verified both from technical and process perspectives
Technically, you can compare the files and structures between a revision taken out of Synergy and a tag taken out of Git. Can we build and verify the software? Can you generate documentation, produce artifacts and releases?
In terms of process, you need to go through a full development and delivery lifecycle in Git to see that you are able to work from the Git base.
Executing the migration
In the previous sections, I highlighted challenges and potential solutions as a result of the different data models. Many of these elements are implemented in our open-source 2git tool which has been used for ClearCase and Synergy migrations.
The migration has two major parts. The first part is to get the source code out of Synergy and into Git without modifications and optimizations. The second part is to optimize the Git repository and add the dependencies.
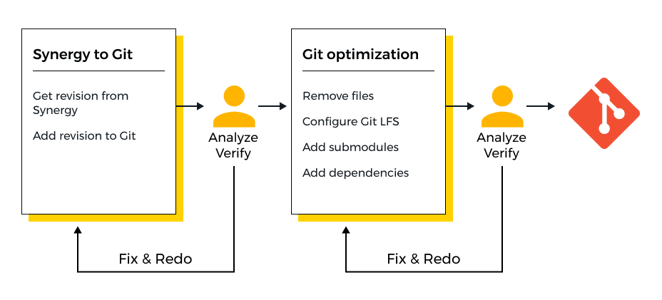
Synergy to Git:
- Run 2git with ccm2git driver. The result is Git history which is not optimized and without submodules
- File and structure compare between the same revision taken from Synergy and Git
- Build software from Git
- Evaluate the result
- Do repository analysis to find files to remove and LFS configuration for phase 2.
One option could be use the git-repo-analyser to files with biggest impact to Git repository
Repeat these steps until you are satisfied with the migration.
Git optimization:
- Update
.gitignoreand.gitattributesfrom repository analysis in phase 1 - Add dependencies to an artifact management system
- Run 2git with git2git-with-ccm-flavour. The result is a Git history which is optimized with submodules.
- File and structure compare between the same revision taken from Synergy and Git
- Add dependencies and tools that are not present in Git
- Based on your decisions. Update the 2git tool to get dependencies and tools
- Build software from Git
- Evaluate the result
Repeat the above steps until you are satisfied
Going live
Delta and partial migrations
For larger organizations, it can be problematic to get team members trained in Git and new processes. In this case, it can be beneficial to do partial migrations. This can either be on project level or it can be based on Synergy releases.
2git can handle delta migrations and only migrate the missing project revisions to Git which makes it flexible and less of a ‘big bang’. I’d advise that you start with top level projects. Firstly, because the top level project does not have any other Synergy projects depending on them and secondly you can verify earlier that you can produce product releases based on the new tool stack, which lowers the risk in the software projects. The subsystems can still release in Synergy and the Git tag/commit becomes available for integration after another run of 2git
Define branching strategy
Synergy and Git are different regarding releases and branches as mentioned. In both setups, a developer delivers changes to a release or branch respectively, but in Synergy there is not such a thing as a default branch or the concept of trunk based development. You might have handled it yourself in Synergy which is great and you can take advantage of the Git way of doing things immediately, by announcing the default branch as the same.
There are many approaches to Git branch management and it’s hard to advise on which route to take without a deep knowledge about your current way of working and constraints.
I suggest that you investigate the migrated history in Git to get a good understanding of how your software assets have evolved over time. You can see very visually how the project revisions and their baselines have developed over time and where there are splits in the history.
Each split indicates a branch, but you are only interested in the potential active branches that will have commits in the immediate future. You can always create more as needed.
Following up
You have now transferred to Git and are reaping the benefits, but it can be hard to change habits.
As an example, organizations tend to continue to do development on release branches. But with Git you could do features on the master branch instead and only create release branches when and if they are needed for maturing. You need to work actively to shift from early to late branching, so you can benefit from a less divergent code base.
Merging is expensive in Synergy and as a consequence you rarely merge the release branches back to the mainline. You might even not merge the changes at all: instead developers are asked to reimplement the same changes on several branches.
You can now create a branching strategy that enables this in an automated manner. Git is both fast and reliable at doing merges. It can even be implemented in your continuous integration platform. I prefer the Git Phlow as it is designed so you can implement changes only once and automation propagates the change to the mainline via trivial merges.
Conclusion
A Synergy migration is usually scary because of the scale and the legacy tooling around it, but it is very much possible with the right knowledge and skills. Experience also helps. We have helped large global organizations through this.
We can also manage your GitLab for you, through our Eficode ROOT managed service.
Published:
Updated:

