Atlassian high availability as code

Containerized Data Center on Kubernetes
How to achieve high availability in a smart, easy to manage, reproducible manner? The solution is ASK (Atlassian Software in Kubernetes).
Atlassian applications quickly become mission critical in a lot of companies. Atlassian provides active/active clustering for many of their applications to support high availability. This is called Data Center.
It can be quite a job managing a clustered setup of these applications. So, you may be asking yourself, how do I manage this in an efficient manner?
Enter “Atlassian Software in Kubernetes (ASK)” - ASK and you shall receive!
The purpose
The basic purpose of Atlassian Software in Kubernetes (ASK) is to:
- Prevent downtime of the Atlassian applications with Data Center
- Provide applications and the environments they depends on as code so they are fully reproducible in an automated fashion
- Provide the deployment as code so it is fully reproducible in an automated fashion
- Provide resiliency
- Provide easy horizontal scaling
- Ease administration costs by having a multi node active/active cluster setup
The target group
You may be saying to yourself - I get all of that with Atlassian’s Software as a Service (SaaS) solution. Maybe so. But there are many businesses that cannot or will not use Atlassian’s cloud solution. Cloud is for relatively small customers of up to around 2000 users, so that is a limitation in itself. But there could be other reasons like:
- There are legal provisions imposed.
- Internal policy, due to sensitive data.
- Limitations of the Atlassian Cloud in terms of plugins, disk usage limitations, etc.
If you have a user base of 500 users or more and you need high availability for your Atlassian applications, but cannot use Atlassian’s cloud solution, this is for you.
Overview of Atlassian Software in Kubernetes
This is a simplified diagram of ASK with Jira Data Center as an example.
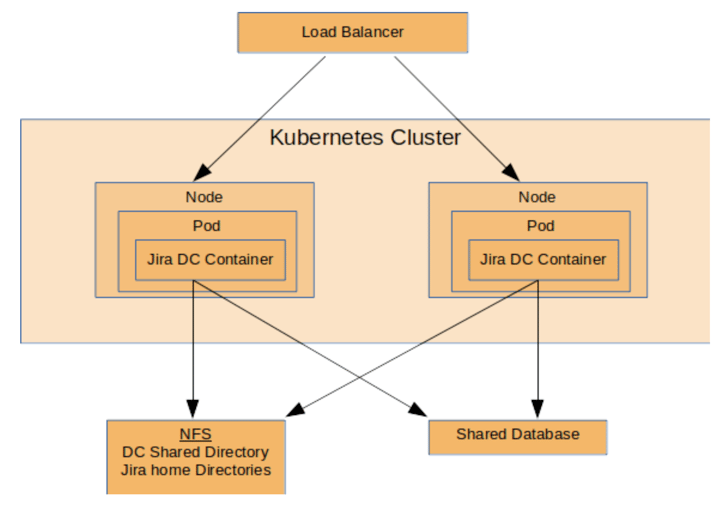
The main takeaways from the diagram are:
- A load balancer is needed for distributing load across the instances.
- The application instances are containers.
- A Kubernetes cluster is used for scaling, resiliency and managing the containers.
- Atlassian’s Data Center solution requires a shared file system and database.
Containerization
If you’ve ever worked with Atlassian products, you’ll know they are Java web applications that are cross platform. This means they can run on a variety of operating systems. However, this does not mean that they do not have dependencies that need to be managed. The applications require a database in a specific version, Java in a specific version, a certain amount of JVM memory, etc. These dependencies may change across versions of the applications. And they need to be managed.
The obvious solution is to containerize the application(s). By containerizing the application(s) we can manage the application, and the environment it depends on, together, as one version.
Docker is the container solution we have chosen for ASK.
High availability
But, containerization is just one part of the equation here. This is also about high availability.
“High availability is a characteristic of a system, which aims to ensure an agreed level of operational performance, usually uptime, for a higher than normal period.”
In this context, high availability is from the user community perspective. They need the ability to access and do their work effectively. But, even if the application is up, it does not mean it is highly available. It could be up but the applications response time is too slow to allow the users to work effectively due to load from concurrent user access. From their perspective it is not available.
To solve this, the application needs to be architected to scale for the load. This is usually handled by architecting the application, so it can be clustered in an active/active manner, meaning multiple active instances running simultaneously and working together to handle the load. An obvious additional benefit is that if one instance goes down there exists other instances which the users can be redirected too. This is exactly what Atlassian has done for many of their applications with Data Center.
But, here’s the kicker! This says nothing about managing the clustered application instances. That is all on you! You have to spin up each node manually and insert it into the cluster. That is a manual task which is error prone and time consuming. If it takes you half a day to do this, is the system highly available from a user perspective? Does that give you resiliency?
So, the question is, how can we manage the containerized active/active cluster in a consistent and easier way?
The answer to this is orchestration of the containers. The tool of choice is Kubernetes. Kubernetes is an open sourced system for automating deployment, scaling and management of containerized applications.
This eases the management of the cluster of nodes. It gives us a way to easily scale to meet load demands. It also provides resiliency as Kubernetes will ensure that a new instance is spun up if one goes down.
How ASK helps you
The easiest way to demonstrate how an architecture like this helps you is to take some simple use cases.
Deploying
As we are using Kubernetes our deployment is defined as YAML files. Assuming we have a cluster ready, a deployment is only about running a single command.
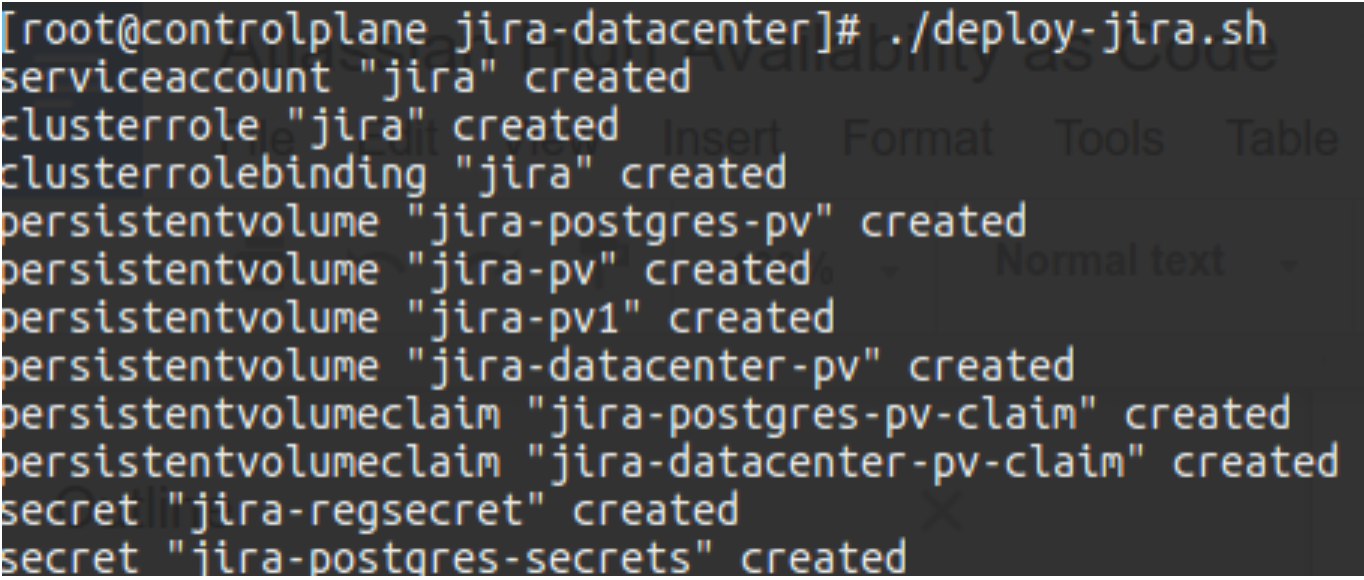
This will deploy the number of instances we have defined in the YAML files along with the PostgreSQL database.

It will do the deployment in an ordered fashion until all the containerized instances are up. Now, that is easy! A time consuming error prone manual task has been automated. Time saved equals money saved.
Scaling
Many of the Atlassian applications start off as small instances used by a few teams within an organization. As time goes by, more and more teams and groups discover them and want to begin using them. Now you need to scale the instance(s) to handle the load. If you haven’t prepared an architecture that will make this an easy transition it can be a difficult process. But, if we start with an architecture that is ready for this, it can be a trivial process.
We take an example cluster with one Jira Data Center instance.
Note: we assume we have another node in the cluster which is not running an instance of Jira. Pretty normal use case for failover scenarios.
Using kubectl we can get an overview of the nodes in our cluster. We can see that we have four nodes (virtual machines) in our cluster. One, which is the Kubernetes master (controlplane.kubernetes), and 3 worker nodes.

Again using kubectl we can get an overview of the actual pods( the holders of our containerized instances) in our cluster. We can see that we have one Jira instance running and one shared database running.

To scale to two Jira instances we only need one command.

Using kubectl again we can now see that we have two instances running.

This operation will take minutes. Basically, only as long as it takes Kubernetes to pull a container image (if it doesn’t already exist) on the node which will run the instance and start the application.
Upgrade
As with all applications newer versions with new features come along. As this is a high availability solution we want to do this with no downtime and we want the process to be simple and painless. If we wait too long to upgrade it causes a wider gap between the versions and makes the upgrade process much harder. We don’t want to build up this type of technical debt!
Atlassian Jira Data Center provides a feature for zero downtime upgrades.

The basic process for this is to put Jira into “upgrade mode,” pull a node out of the cluster, upgrade it, and bring it back into the cluster. You do this for each node in the cluster. After which you finalize the upgrade.
Great feature! But this is even easier if we have containerized our applications. We do not need to manually upgrade the nodes.
We simply change the version in our Dockerfile, build and push it. Edit our Kubernetes deployment YAML file with the new wanted version of the Docker image and apply it. Then we put it into upgrade mode and start killing pods.

Kill off Jira-1. Kubernetes will notice this and spin up a new instance with the newer version we have applied.

Now we wait for the new version of Jira-1 to come up and check the version.

Then we simply repeat the process for the other nodes until we are done.


Finally, we set Jira upgrade to done by hitting the “Run upgrade tasks”. Simple!
Summary
If you need high availability with Atlassian application(s), you should use Atlassian’s Data Center solution. We would encourage you to follow the links and read up on it.
Downtime costs money in this scenario. The less downtime we have, the higher the business value. And if you have several thousand users effectively blocked from doing their work it will not take long before it becomes costly.
Containerizing Data Center enabled Atlassian applications and using Kubernetes to orchestrate them gives everything as code and is a DevOps approach. It provides easier scaling and management of the applications and it will save you a lots of time and money.
We can help you implement Atlassian Software in Kubernetes, and have expertise in the whole Atlassian toolstack, as Atlassian Platinum Solution partner.

Published:
Updated:
