From Monolithic to Modular

How to safely introduce modular architecture to legacy software
In software development tight coupling is one of our biggest enemies. On the function level it makes our application hard to change and fragile. Unfortunately, tight coupling is like the entropy of software development, so we have always have to be working to reduce it.
Introduction
In this blog post I will explain how to introduce modular architecture to a legacy system. Our goal is to present a process that will take us from the most tightly coupled system, a monolith, to the most loosely coupled system our organization will allow. We want separate teams to be able to deliver and test separate components to enable smaller batch sizes and shorter feedback loops. We also want our system to be robust and easily scalable.
Starting point
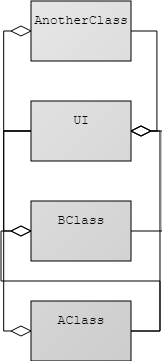
For this guide to apply a few things need to be true. We assume that the system is business critical and is currently in use. We assume that there is more than one development team working on the system. Usually these teams get feature requests with business value or prioritization attached. We also assume that we are working in a compiled object oriented language, such as Java or C#. Most of this applies to any style that has data encapsulation, e.g. services communicating through REST. We also assume that the source code is in version control.
Constraints
We work with real software developed and used by real people, so there are a few human constraints that we need to acknowledge to make this transformation practical.
Conway’s law
Conway’s law states that an organization produces software that mimics its communication structure. This means that splitting up our software is not enough. We need to make sure that communication in our organization is determined by the business in a way that matches the structure we want to see in the code. If we want to decouple the modules we need to decouple the teams.
Always “Green”
Usually “green” refers to passing tests, but here we use the term more generally to mean that the system is working. We are “green” if the software is running and users are able to use it. We do not assume that the software has automated tests. When working with a business critical and running system it is not an option to shut it down, refactor it, and open it again. People depend on the system to do their job, so we need to make sure that during the entire process the system stays green. One way to make sure we are green is through comprehensive testing, but in some situations this isn’t possible. Here we need to get as much help as we can from other tools, like the compiler, and should a critical issue appear we have to be able to fix it with minimal overhead. Maintain Level of Service Maintaining the level of service both in terms of performance, functionality, and error rate is also an important constraint. The system should not get noticeably worse during the transformation. In fact, it should end up being better.
Step 0: Identify Modules
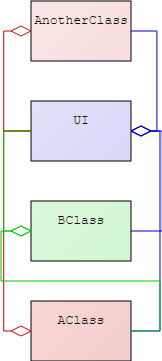
If we want each team to deploy independently we first need to determine what they are deploying. Let’s keep Conway’s law in mind - the modules of our code will mimic the communication of our organization. Optimally, we want to communicate lots within our team and much less with other teams, but this doesn’t work when we do not have the data or access we need.
We need to divide up the functionality of the application in such a way that we limit the need for cross-team coordination and hand-offs. It can be difficult to find a good distribution of responsibilities but a helpful technique is to begin by looking at the data. Have every team stipulate what data they should own and then give it to them. Most data will be claimed by only one team, but some of it will be claimed by multiple teams. In this case we have three options. If the data is required by a large proportion of more than one team then it might make sense to merge them. If it is around a third of both teams then maybe the two teams should be three teams, with one taking the common part only. If it is small for both teams it is probably best to duplicate the data.

Step 1: Isolate Modules
Having identified which modules we want we need to make them independent. We do this in steps, the first of which is to create a single point of entry. This single point of entry tells us exactly what our current external interface is. Having a single point of entry also enables us to change the internal working as much as we want for as long as the external interface stays the same. This makes us less fragile. To do this safely we create an empty class, the façade. We now make every method in our module accessible within our module only. This causes the compiler to generate errors wherever we use a method from outside the module. For each of these errors we simply change it to call a new public method in the façade. It can now call the internal method because it is in our module.
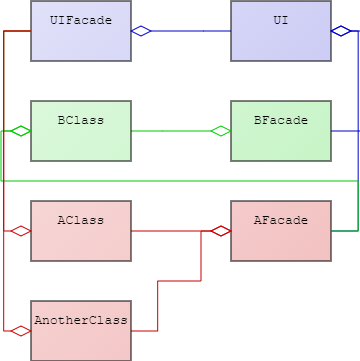
Step 2: Reduce Communication
The next step is to reduce the communication between modules. We do this by pushing functionality as close to the data as possible. Instead of requesting data and then transforming it, move the transformation to the data and request the result. This applies to inside modules and across module bounds. Pushing the functionality also means that we eliminate most of the need to return values. As the computation comes closer to the data we are able to pass it as parameters and call further. Several refactoring patterns exist to help with this, but they are out of the scope of this post. For further reading on this specific task see:
- Wiki: Law of demeter,
- Github: Kata,
- Book: Refactoring by Martin Fowler,
- Book: 5 lines of code by Christian Clausen.
Step 3: Eliminate Direct Communication
The only thing preventing us from deploying separate modules at this point is the circular dependencies caused by calling modules that in turn call us. After the last step it is easy to switch to a complete push based system. We introduce a central message queue that everyone can push to. We also add an observer class to each module which can look at the message queue. Whenever a relevant message enters the message queue the observer calls the relevant method in the façade. We now make the methods in the façade accessible only within our module, like we did earlier. Again, the compiler tells us everywhere we use the façade, and here we instead push the relevant type of message to the central message queue. If the message queue is very simple we might not need to maintain it at all. This is the case if we use a cloud solution, or if it is a regular queue internally. Otherwise we need to dedicate a team to maintaining that too. Now everything has only one dependency: the central message queue, which has no dependencies. We can now move our modules to their own projects, in their own repos, and compile them separately of everything - other than the message queue. That means that we can also deliver our dll, jar, or service, independently.
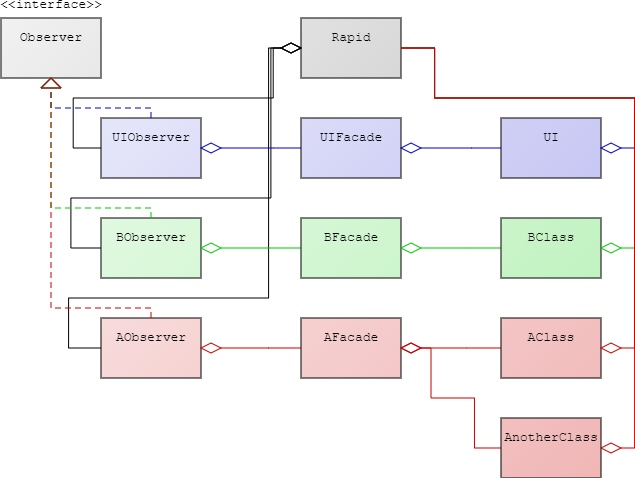
Common Challenges
There are a few challenges that arise from this transformation. Here we will go through the most common.
Inter-team Communication
As discussed earlier - due to Conway’s law - changing our software is not enough. We also need to manage how the organization communicates, particularly between teams. As our architecture is through a central message queue the communication should follow the same pattern - a central API documenting every method that the system supports. As our system is now push based our communication should be too. We make feature requests to other teams. Then we use our favorite agile process to develop the new feature. When the feature is finished the developing team publishes information about new types of messages which accommodate our needs on the central API. This should be the only professional communication needed.
Dependencies and Versioning
Our goal was to decouple components so we could deploy them separately. This naturally entails the question of how to keep them in sync with each other. We usually solve this by treating it as if it were a REST API. We encode the version number in the message. Then each observer is responsible for calling the appropriate method in the facade. This means that our code might have multiple versions of the same functionality simultaneously, for as long as we need to support it.
Testing
Commonly splitting up an application like this exposes untested or poorly tested parts of our code. As with the functionality we should strive towards moving tests as close to the data as possible so that each time something fails we should ask: “how can we push this error one level closer to the data?”
For completeness we show relevant levels of testing:
- Unit tests methods inside a module. Owned by the team or developer.
- Component tests that a message to a module results in the right message(s) being pushed on the message queue in the end. Owned by the team.
- Integration tests that multiple components handle messages correctly. Collectively owned by teams involved.
- System tests for functionality involving most or all components. Owned by the organization.
- Production tests if the system works. Owned by the organization.
Conclusion
At this point we have a number of teams, each with a module that they can build and deliver independently. We have made the system less fragile by isolating each module. Further, if we want to scale horizontally, we can easily modify our observers to use an internal work queue, and attach more instances of the module to this.
This system even supports dynamically adding new functionality in the form of plugins. This is because we can subscribe to the same messages that the system uses, orinvent new ones, without changing or affecting any of the existing code. We have also taken care to keep the system in a running state from start to finish. The things we have broken have always been locally, between commits. Thus there should have been no effect on production. When we have broken things we have done so in short bursts, and each time with help from the compiler. Potentially, we have also opened up new opportunities in terms of infrastructure. If we started with a single application we now have the option to make the central message queue available over the network and deploy services to different servers, thus creating a microservice architecture. We can even split up our modules to make each function in our façade into its own mini-module that can be deployed separately. This would be a serverless architecture.
Getting here can involve a long process, but Rome was not built in a day. The benefits of smaller batch sizes, more robust code, and the shorter feedback cycles that this transformation enables, makes it well worth the effort.
Published:
Updated:
