Have you closed the DevOps infinity loop after deploy?

Product organizations have had their focus on DevOps for a long time. But how much energy do they actually spend on the Ops part of it?
Can we close the DevOps infinity loop with IT service management?
The “wall of confusion” has two sides. One faces development, while the other faces operations. When this wall is illustrated, we usually see a flow in the direction of development to operations and rarely in reverse.
DevOps, however, is illustrated in a completely different way–taking the shape of an infinite loop and describing the areas we need to cover and what capabilities we need to have as a product or service organization. As we all know, DevOps is about tearing down the “wall of confusion” and change the way Dev and Ops work together. We strive to build a culture where Dev and Ops collaborate to deliver value-creating code frequently (and high in quality) with the entire flow going from discover to continuous feedback.
But with your hand on your heart, answer me this. Do we really focus enough on what happens after Deploy? Don’t we miss out on a lot of things related to interaction between Ops and Dev?
This blog is about connecting the DevOps loop and bringing focus to the Ops side and how it can feed into product discovery. I also want to go over how we can work with IT service management (ITSM) to gain insight into ways of providing high service quality and value to customers.
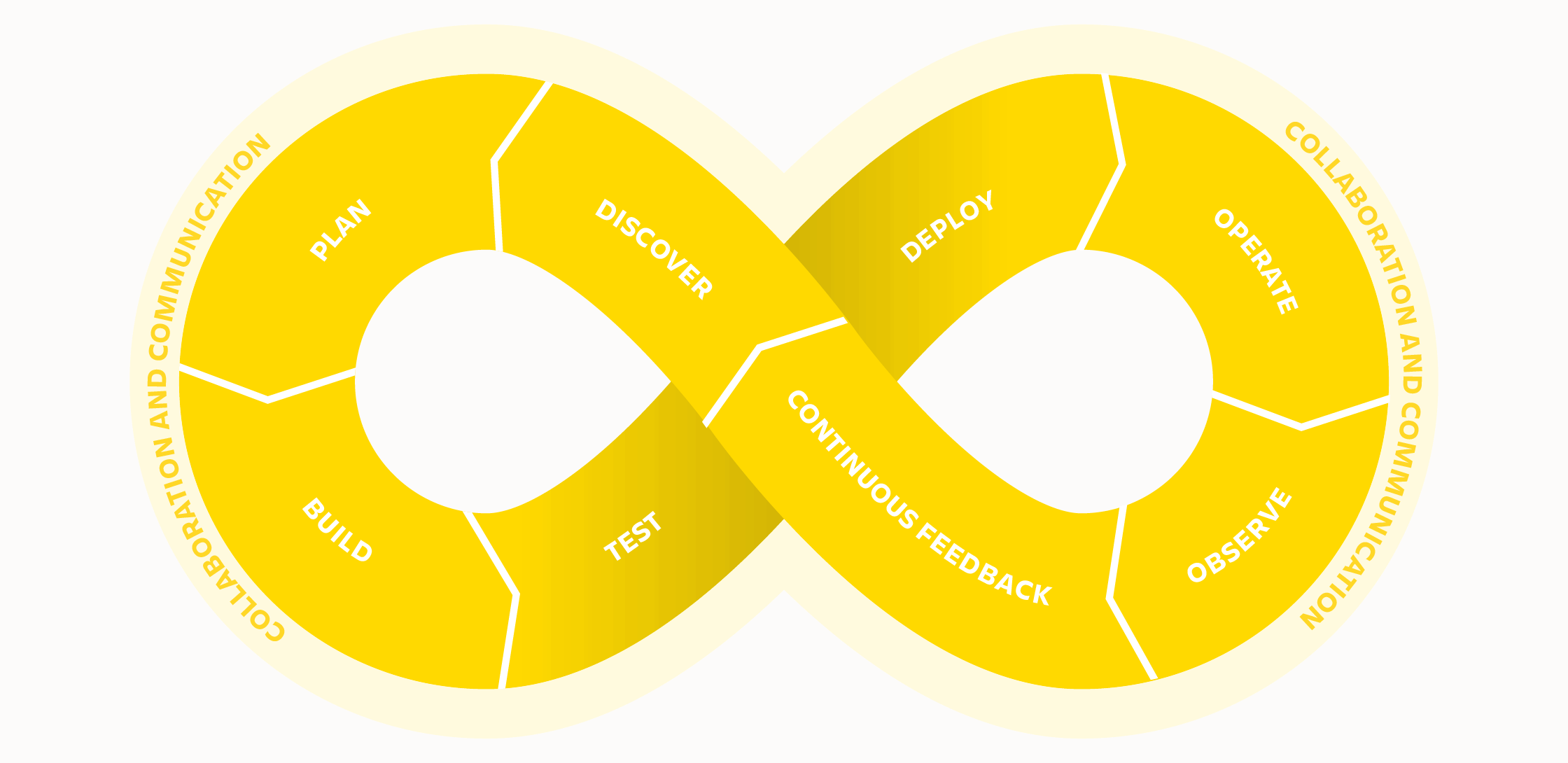
What do we mean by operations in DevOps?
If you asked ten people this question, you would probably get ten different answers. Personally, I would summarize it to be the practice and capability of making sure that whatever is deployed is managed and available with the right capacity and level of security.
Who does what in operate?
When code is deployed in production and confirmed to be working, the operations teams are responsible for making sure everything is online. This is done differently depending on the architecture of the services provided. Is everything on-premise or is there a mix of infrastructure-as-a-service (IaaS) and platform-as-a-service (PaaS) for the different parts of the service? Is the operation team in-house, outsourced, co-sourced, or multi-sourced?
It really doesn’t matter, but we need to pay attention to the collaboration perspective and management of expectations between the different stakeholders.
What does matter is that we need to ensure that we get the information from all parties to make decisions and prioritize what work needs to be done. For example, we want to be able to make decisions to avoid building up a technical debt, and make sure that changes in the environment aren’t disrupting the services provided.
Here, collaboration between Dev and Ops is crucial to making the right decisions and providing insight into Product Discovery. There are a lot of different tools in the marketplace that are used for the operate part of DevOps, with each tool providing different data and information in various ways–all with different purposes.
In ITIL4 (which is a framework for ITSM), there are some principles that relate to this topic:
- Collaborate and promote visibility
- Keep it simple and practical
We need to ensure the data and information provided by the operation tools are available and easy to use for the stakeholders, whether it is a product manager, product designer, or product lead engineer. This will improve their ability to manage and improve the services well.
As an organization, you also want to be sure that decisions are made at the right level, with operational decisions being made as close to the operation team as possible (preferably within the team), which will empower the team to be more autonomous and Agile. If you want high-velocity IT Service Management, you need to remove waste like hand over and wait as much as possible. Trust your teams, regardless if they work with Dev, Ops, or DevOps.
How do we observe?
Let's start off with a question. Why do we observe? If the answer is just “We want to monitor our application performance”, then it’s not helping from the perspective of ITSM or DevOps. We must be clear about what we intend to do with the information we get from our observations, as well as who can and will use it.
We also need to be able to answer the questions if the result we got was good, bad, and expected. The main reason for observation and monitoring is to improve what is observed, which includes fixing things that are broken.
Continuous improvement is a central capability within Lean, DevOps, and ITSM. Therefore, we need to ensure the tools we use for observations are providing relevant information to be able to find areas for improvement. This information is crucial for product managers, product designers, or product lead engineer's who are responsible for making sure we continuously improve our services.
We want to empower them to act on deviations identified through observation to make sure we don’t miss out on technology improvements, changes needed in ways of working, tooling, or partner collaborations.
So, what do we observe in a DevOps environment? If we look at the metrics in a DORA report, it covers:
- Deployment frequency (How often a software team pushes changes to production)
- Change lead time (The time it takes to get committed code to run in production)
- Change failure rate (The share of incidents, rollbacks, and failures out of all deployments)
- Time to restore service (The time it takes to restore service in production after an incident)
The last two points are tightly related to ITSM, with the first relating to the ITIL practices of change control and incident management and the last on incident management. This means we need to monitor incidents and changes in the product environment and the capability to relate them to each other to get the ITIL quality KPI of incidents caused by change. Some of this can be automated by integrating the CI/CD pipeline to change control in, for example, Jira Service Management.
What else do we need to observe to improve the services we provide to our customers? That list could be very long, but how about user support interaction, utilization of available service functions, and product user experience?
It’s crucial for product organizations to measure the usage of different features and frequency of people using the standard service to be able to find new opportunities for further development. Product managers, product designers, and product lead engineers need ways to identify what creates value for the end users to eliminate all backlog activities that don’t create customer value.
Some studies point out that it’s not uncommon for a third of the backlog to not create end user value; they are just waste taking up space from what is.
A common mistake when working with monitoring and observation is to miss out on covering different dimensions of the deviations' root cause. In ITIL, there is a practice called problem management that is closely related to continuous improvement, and the objective of that practice is to manage recurring quality issues like incidents. In that practice, when working with problems to find their root cause, it’s essential to analyze them in four dimensions:
- Organizations and people
- Information and technology
- Partners and suppliers
- Value streams and processes
In technology and product organizations, it’s not unusual to see only information and technology covered when conducting a root cause analysis. This dramatically limits the capability to find the actual root cause, eliminate it, and improve the service quality. If you don’t analyze in all dimensions, the same type of technology deviation likely turns up again and again.
How can we work with continuous feedback?
Much of the information and data we gather in Ops can be put in reports and dashboards for us to be data-driven or analyzed by AI. But we also need to have forums for collaboration and dialog to learn from each other. A good way to achieve this is to have customer support teams meet Dev and Ops teams regularly; to share thoughts and build good cross-functional relationships. This in turn creates a culture of collaboration and transparency that are fundamental principles within ITSM, Agile, Lean, and DevOps.
What we find during operation and observation needs to be assessed, evaluated, prioritized, and documented to be helpful in our feedback loops going into product discovery. We need to structure data into information and add context to create knowledge that will be the basis for decision-making. Opportunities need to be presented, value needs to be identified, risks need to be managed and everything needs to be in a good state for product discovery to evaluate, prioritize, and make decisions on.
Closing the loop
At this last stage, I believe we’ve made great progress in closing the DevOps infinity loop from deploy to product discovery. Of course, there aren’t any silver bullets or magic solutions that fits every organization. But every organization can identify and take steps towards a complete DevOps way of working that’s tightly integrated with ITSM practices and the work Ops are doing.
The first step is to assess and identify your strengths and weaknesses in working, tooling, and culture.
Summary of actions to consider
Collaboration and dialogue
Bring together different teams (Customer support, Development, and Operations) together to share insights and build cross-functional relationships. Create a culture of collaboration and transparency with foundational principles from ITSM, Agile, Lean, and DevOps.
Structured data transformation
Transform raw operational data into structured and meaningful information, putting the information into a context to create knowledge to use as the basis for decision-making.
Prioritization and evaluation
Assess, evaluate, and prioritize observations from operations, which ensures only the most crucial feedback makes its way into the product discovery phase.
Integrate feedback into product discovery
Build ways to use the information from Observe and Continuous feedback during the product discovery phase to evaluate, prioritize, and make decisions. This ensures what you learn in the operation phases is utilized when evaluating new features or improvements.
Continuous observation and monitoring
Use observation tools that provide relevant information to everyone in the DevOps infinity loop (especially operation engineers, product managers, product designers, or product lead engineers). Empower teams to act on deviations and improvements identified through observation.
Root cause analysis
Ensure a you conduct a full root cause analysis by considering all four dimensions listed in ITIL4:
- Organizations and people
- Information and technology
- Partners and suppliers
- Value streams and processes
Don’t limit this just to cover the technological dimension. By taking every dimension into consideration, teams can holistically understand and address all underlying issues.
Get continuous improvement in your DNA
The primary reason for observation and monitoring is to improve what's observed continuously. Make sure this mindset is in your organization's DNA and encourage your teams to be proactive with feedback to promote and enable continuous product improvement.
Integrate and build analysis capabilities
Ensure your tools are integrated to enable the automation of measures and metrics. One example of this includes integrating your CI/CD pipeline with your ITSM tool to utilize the ITIL practice of change control.
Close the feedback loop
Communicate, communicate, communicate. Ensure your operation information doesn’t get stuck in silos and have it flow from Operate to Product Discovery to close the DevOps infinity loop.
Published:
Updated:

