Kickstart your startup with serverless

When choosing a tech stack, startups look for cost-efficient and scalable solutions. Serverless can be a great option, but how do you get started with it?
What’s the thing early stage startups don’t have? That’s right, servers! Sorry, I meant to say money, which is why they should forget about servers and kickstart their business with serverless. And by servers I don’t just mean your antiquated server racks or EC2 instances running your LAMP stack, I mean your fancy GKE Kubernetes clusters. Pay the extra 50 bucks to run a minimal Kubernetes cluster that only serves your frontend and a few NodeJS microservices responding to rather infrequent traffic if you really want to. But why do that when you can do all of the above at a fraction of the cost and reduce maintenance overhead?
In this blog post I’ll show you how to get started with all of this in 10 minutes. More precisely, we'll focus on getting you and the rest of the developers coding collaboratively on your world-changing product. At the end of this post you'll have a repository that includes a serverless API running on AWS and a react frontend that utilizes the API.
The Serverless Framework
We'll be using the Serverless Framework to create our serverless API to AWS. Serverless framework isn't bound to only AWS as it supports all the major cloud providers and cloud provider agnostic technologies such as Kubeless.
When working with AWS, the Serverless Framework uses Cloudformation under-the-hood to set up our serverless stack. It is quite easy to add custom Cloudformation-resources to our serverless deployment when using the Serverless Framework. For example, we could create a Cloudformation template to create a DynamoDB-table that our lambdas can utilize and deploy together with our lambdas just by running a single “serverless deploy” -command.
Enough talk, let’s get the lambdas running!
Let’s get started
The project is configured in a way that makes it easy to collaborate with others. In practice this means that it is easy to create personal copies of the serverless API, develop new features against it, and automatically configure the frontend to utilize your own serverless Rest API.
Clone this repository: https://github.com/severi/serverless-react-getting-started
and checkout the tag step1
$ git clone git@github.com:severi/serverless-react-getting-started.git
$ cd serverless-react-getting-started
$ git checkout step1
In the repo I have provided you with a basic create-react-app boilerplate project for the frontend (frontend-folder) and a simple serverless-framework example for the backend (api-folder).
The frontend part was created by running (see more information):
$ npx create-react-app frontend
Running the frontend
First, let’s verify that the frontend can run correctly. To do so, run the following commands:
$ cd frontend
$ npm install
$ npm run start
And we're good to go! Now that we have our frontend running successfully you can stop it, unless you wish to admire the awesome create-react-app landing page for a lil' longer. We'll be focusing on the serverless part and come back to the frontend later on.
Getting our serverless API up and running
Next, we have to tool up! Install the Serverless-framework CLI
$ npm install -g serverless
We need to configure our AWS credentials and create an AWS account if you don't already have one. Fortunately, serverless.com provides thorough instructions regarding this, so no need to copy and paste them here. Just follow this link and come back when you're ready.
Deploying the function
From the api folder, let’s run sls deploy to get our function up and running on AWS. Your output should look like this:
$ sls deploy
Serverless: Packaging service...
Serverless: Excluding development dependencies...
Serverless: Creating Stack...
Serverless: Checking Stack create progress...
.....
Serverless: Stack create finished...
Serverless: Uploading CloudFormation file to S3...
Serverless: Uploading artifacts...
Serverless: Uploading service serverless-api.zip file to S3 (714 B)...
Serverless: Validating template...
Serverless: Updating Stack...
Serverless: Checking Stack update progress...
................................
Serverless: Stack update finished...
Service Information
service: serverless-api
stage: dev
region: eu-north-1
stack: serverless-api-dev
resources: 10
api keys:
None
endpoints:
GET -
https://XXXXXXXX.execute-api.eu-north-1.amazonaws.com/dev/myfunction functions:
myFunction: serverless-api-dev-myFunction
layers:
None
Serverless: Run the "serverless" command to setup monitoring, troubleshooting and testing.
Now our function is running on AWS we can try to trigger it. We’ll use curl for that. The function’s url can be found from the output of the sls deploy command. Check the endpoints: section. As we can see, it indeed is running:
$ curl
https://XXXXXXXX.execute-api.eu-north-1.amazonaws.com/dev/myfunction {"hello":"world"}%
Explaining what's happening
The api structure is simple:
$ tree -I node_modules
.
├── functions
│ └── myFunction.js
├── package-lock.json
├── package.json
└── serverless.yml
1 directory, 4 files
The interesting parts here are the serverless.yml and functions/myFunction.js files. In the following sections we describe each in detail.
serverless.yml
Our serverless.yml consists of three sections:
- service - Defines the name for our serverless stack
- provider - AWS related configurations
- functions - our serverless functions that we wish to deploy
service: serverless-api
provider:
name: aws
runtime: nodejs10.x
stage: dev
region: eu-north-1
functions:
myFunction:
handler: functions/myFunction.main
events:
- http:
path: myfunction
method: get
We deploy one function called myFunction. The handler section defines where the code for the particular function can be found and translates to "function main in file functions/myFunction.js”.
handler: functions/myFunction.main
functions/myFunction.js
The function we deploy is simple. It just returns a { hello: "world" } json object.
exports.main = async function(event, context) {
return {
statusCode: 200,
body: JSON.stringify({
hello: "world",
})
};
}
In the events subsection we further specify that myFunction should respond to HTTP GET requests to the following path /myfunction.
As a reminder, this is how we test our function. Notice how the url is ending:
$ curl
https://XXXXXXXX.execute-api.eu-north-1.amazonaws.com/dev/myfunction
{"hello":"world"}%
In the provider stage we also define the default stage to be “dev”.
stage: dev
This can be overwritten by adding the --stage stagename flag to the sls deploy command.
Stages are useful for creating separate development or testing environments. See this for complete serverless.yml reference.
AWS
So, what happens on the AWS side? The Serverless Framework uses Cloudformation in the background to deploy our serverless-stack. To verify this you can open the Cloudformation-section from the AWS Web UI: https://eu-north-1.console.aws.amazon.com/cloudformation/home
See how the serverless creates a Cloudformation stack based on the service and stage names we have provided?
If you navigate to the Resources tab of our freshly created Cloudformation stack, you can see what kind of AWS resources were created during the deployment.
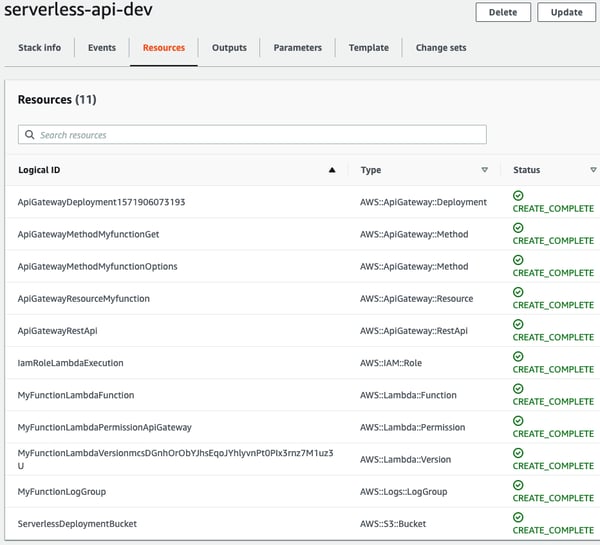
These resources include:
- ServerlessDeploymentBucket
- The S3 Bucket that our lambda code is copied to
- API Gateway
- this is what the https://XXXXXXXX.execute-api.eu-north-1.amazonaws.com/ part of our lambda url refers to
- IAM Role
- Allows our lambda function to write its logs to Cloudwatch
- MyFunctionLambdaFunction
- The lambda function itself
Coherent code style
One of the benefits of using Node.js is that we can utilize the same programming language and libraries both for the frontend and the backend of our application. Our frontend already uses the latest ES6 Javascript features. To take advantage of the same features in the backend services and make our coding style coherent between the frontend and the backend functions, we’ll need to add our first plugin to our serverless.yml : the serverless-bundle. You can find more information regarding the differences ES6 introduces to the Javascript syntax here.
$ cd api/ $ npm install
--save-dev serverless-bundle
As recommended by the creators of the serverless-bundle in their own serverless guide, we are also going to enable individual packaging for our functions.
plugins:
- serverless-bundle
package:
individually: true
By enabling the individual packaging together with the serverless-bundle-plugin we are able to create single optimized packages for each of our functions -- OK, currently there's only one, but in a real life application you'd end up with many.
Now we can convert our myFunction.js to utilize the ES6 syntax. As our example function is quite simple, the difference between the ES5 and ES6 implementation is limited to the way the function is declared, but in a larger codebase this would of course have a bigger impact.
export const main = async (event, context) => {
return {
statusCode: 200,
body: JSON.stringify({
hello: "world",
})
};
};
Let's redeploy our function:
sls deploy
The serverless-bundle, among other things, also enables eslint for our serverless project. You can test this by removing the trailing semicolon from our function and then try to redeploy it. You should see something like this:
/Path/to/serverless-react-getting-started/api/functions/myFunction.js
9:2 error Missing semicolon semi
✖ 1 problem (1 error, 0 warnings)
1 error and 0 warnings potentially fixable with the `--fix` option.
What's the best way to fix these issues? We could of course fix them manually, but in the long term this can get tedious. We definitely would like to fix these issues automatically, if possible.
Unfortunately, I have not found a way to:
- show the linting errors in Visual Studio Code
- actually run eslint with the --fix flag by directly using the eslint configurations the serverless-bundle introduces.
As a workaround I've done the following:
$ cp ./node_modules/serverless-bundle/src/eslintrc.json .eslintrc.json
and added the following scripts to the api's package.json
"scripts": {
"lint": "node_modules/.bin/eslint --ext .js ./",
"lint:fix": "node_modules/.bin/eslint --ext .js ./ --fix"
},
This overrides the eslint configurations with the same configuration that the plugin is using. Therefore, because we have the .eslintrc.json file at the root of the api-folder, the linting will work both via CLI and VSCode.
We can now automatically fix the auto-fixable linting issues by running:
$ npm run lint:fix
In real life it would make sense to standardize your linting so that both your frontend and serverless code are linted with the same settings. This way you can achieve a coherent coding for all your javascript files.
For a complete solution for this stage checkout tag step2
$ git checkout step2
Calling the serverless function from our website
Let’s edit the `App.js` file from our frontend and add code that calls our lambda.
import React from 'react';
import logo from './logo.svg';
import './App.css';
function App() {
const onClick = async () => {
const response = await fetch("https://XXXXXXXX.execute-api.eu-north-1.amazonaws.com/dev/myfunction");
const data = await response.json();
console.log(data);
}
return (
<div className="App">
<header className="App-header">
<img src={logo} className="App-logo" alt="logo" />
<button onClick={onClick}>API call</button>
</header>
</div>
);
}
export default App;
This alone isn't sufficient because we'll get a CORS error -- try clicking the button, open the console of your browser and you'll see the error message. CORS comes from the words “Cross-Origin Resource Sharing”, and it makes it possible for requests to be made to domains other than the one in which your website is running. You can read more about CORS here.
If we take a look at the serverless.yml reference from https://serverless.com/framework/docs/providers/aws/guide/serverless.yml/ we see that we can add the following option to our function:
cors: true # Turn on CORS for this endpoint, but don't forget to return the right header in your response
As the comments state, we need to modify our response as well. Adding this header means that we can do cross-origin requests from our awesome web application during development i.e. from http://localhost:3000.
export const main = async (event, context) => {
return {
statusCode: 200,
headers: {
"Access-Control-Allow-Origin": "http://localhost:3000",
},
body: JSON.stringify({
hello: "world",
})
};
};
Redeploy the function. Now the button-click should correctly print the response to the browser’s console.
Less hard coding, more collaboration
Hard coding the API url to our frontend code is not optimal. In the production build of your application you'd like to target the production-version of your API. In development you and your colleagues should each use your own versions.
In order to enable this let's extract the hard coded URL from the code to an environment variable by changing the fetch line in our App.js to the following:
const response = await fetch(`${process.env.REACT_APP_ServiceEndpoint}/myfunction`);
As some of you might have noticed, we are going to use the custom env-variables functionality provided by create-react-app to embed our service endpoint as an environment variable during the build time (for more information).
Next let's define the REACT_APP_ServiceEndpoint variable. We'll be using the .env.development.local file to do this (more info regarding different .env-files and their priorities here).
We can create the file manually and add the following line to it
REACT_APP_ServiceEndpoint=https://XXXXXXXX.execute-api.eu-north-1.amazonaws.com/dev
This is fine with only one developer and one environment variable, but what if we need more information regarding our AWS stack in the frontend later on? Perhaps you’d like to allow users to upload files to S3 directly from their browser without invoking any lambdas. Also, how do we communicate these manual steps to other developers so they can set up their own development environments?
Fortunately, the creation of the env-file can be automated.
To automate this we'll be using a custom fork of a plugin called "Serverless Stack Output Plugin". According to the plugin’s README it does the following:
store output from your AWS CloudFormation Stack in JSON/YAML/TOML files, or to pass the output to a JavaScript function for further processing.
Using our fork of the plugin, we can generate our create-react-app environment files automatically during the deployment step of our serverless stack.
Let's install our custom version of the serverless-stack plugin by running
$ npm install --save-dev @severi/serverless-stack-output
and modifying our serverless.yml like this:
plugins:
- serverless-bundle
- '@severi/serverless-stack-output'
custom:
stage: ${opt:stage, self:provider.stage}
output:
file: .stack.${self:custom.stage}.react_app # using our custom .react_app -format here
If we deploy the API again by running sls deploy, you'll see that we also get a file called .stack.dev.react_app. Let's copy it to the frontend-directory and rename it
$ cp .stack.dev.react_app ../frontend/.env.development.local
and we're done!
Restart the frontend and check that it still prints the hello-world object to the console. With this approach it is easy for a single developer to create a new serverless-environment by defining a custom stage during the deployment (e.g. sls deploy --stage myenv), use the generated file to define the environment variables for the frontend, and bind it to the new serverless backend. This is not limited to just the serverless functions and their API Gateway url, but to other AWS resources created with the serverless-framework as well.
For the production build the environment-variables can be put in .env.production and stored in version control.
For a complete solution for this stage checkout tag step3:
$ git checkout step3
To delete the serverless stack from AWS, run:
$ sls remove
If you want to be extra careful, check the Cloudformation page in the AWS console and verify that all stacks created by the serverless framework have been deleted.
Conclusion
Getting started with serverless does not have to be difficult. It is still a new field and therefore the technology and best practices around it are continuously evolving. I hope this tutorial has made your journey with serverless a little more understandable, and you are now able to start new serverless projects and develop them in collaboration with your colleagues.
Technical debt is a reality in every company, and while it’s not the end of the world the decision to take it on should always be deliberate. Having your infrastructure as code and automating provisioning should be high on your to-do list from early on. Luckily for us, this is something the serverless framework with cloudformation helps us to achieve.
Serverless is a great tool in a developer’s toolchain, but serverless is not always the most cost efficient solution (for more information see this blog and that blog on going serverless). However, when used for the right purposes, it allows us to create cost efficient and automatically scalable services. And, as you’ve seen in this blog post, getting started with it is pretty straightforward.
If you’d like to learn more about the topic, here is a great tutorial to start with. Perhaps we’ll also cover some other aspects of serverless development in future blog posts. Meanwhile, now is the time to stop wasting money on underutilized servers and start your serverless journey!

Published:
Updated:
