Azure OpenAI and your Atlassian data

Building an AI business case
For a while now, we’ve talked about OpenAI, different possible business cases, and what we could do with it. Almost always, the problem was that the business case required specific data or was hard to prove it would be correct.
With new technology, getting started quickly is important, so we wanted to make as simple a business case as possible. After careful tuning and work, I came to the conclusion that we would need to know who’s done this before. A simple question, but often with multiple answers.
For us, it can theoretically be done with JQL as all of the data lives in Jira Service Management, but it only considers the assignee field and not, for example, our time-tracking data from Tempo.
So by asking the AI, “Who has previously worked with Exalate?” you’d get 10 names and would know whom to ask for help. If this can be answered, we theorized it would save hours of time per month due to often just needing the correct person to help you get started with a case. Our marketing has additional business cases for me, which include the “top 25 most commonly faced issues.” If we can answer that question, they would be happy.
Azure OpenAI and your own data setup
A quick napkin architecture showing what we need for Azure OpenAI.
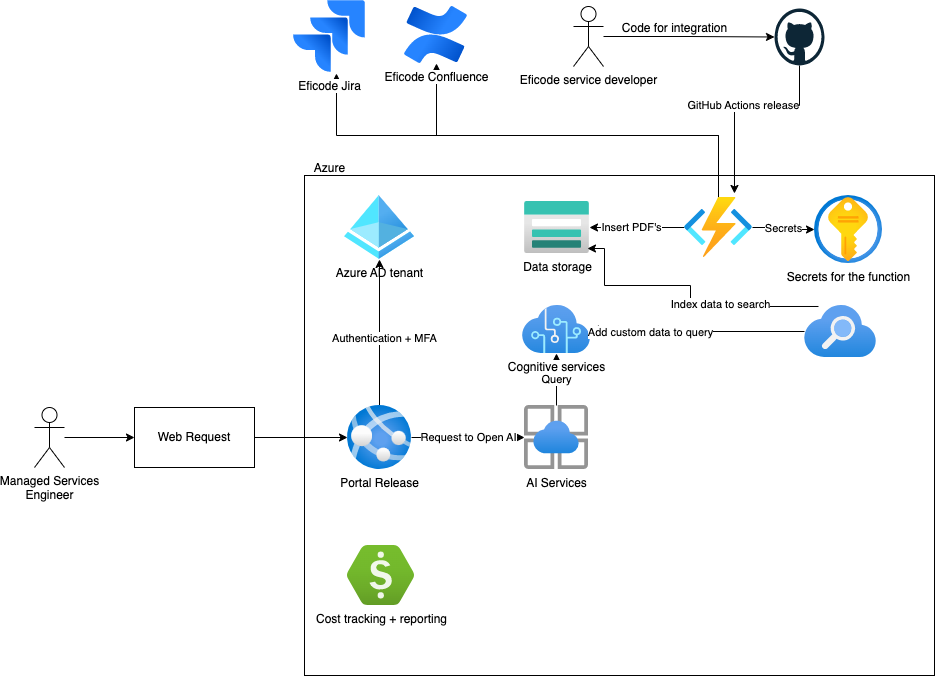
The end result of the Azure OpenAI ends up looking like this for testing your data and chat before releasing it to the wild. This means we have few components here.
In this section, we’re going to focus on the Cognitive services + Azure Search with Blob Storage and AI Studio. Then, we’ll look at the integrations and finish by talking about releasing your AI.
All of this really starts by applying to have OpenAI available to your organization, which requires you to fill out a form and agree to follow ethical AI programs. This enables the Azure OpenAI to your subscription. After this, we can start working on the product. I started by going to the Azure OpenAI Studio and opening the Chat playground to have our first query and testing. You can see the end result of chatting to the AI below.
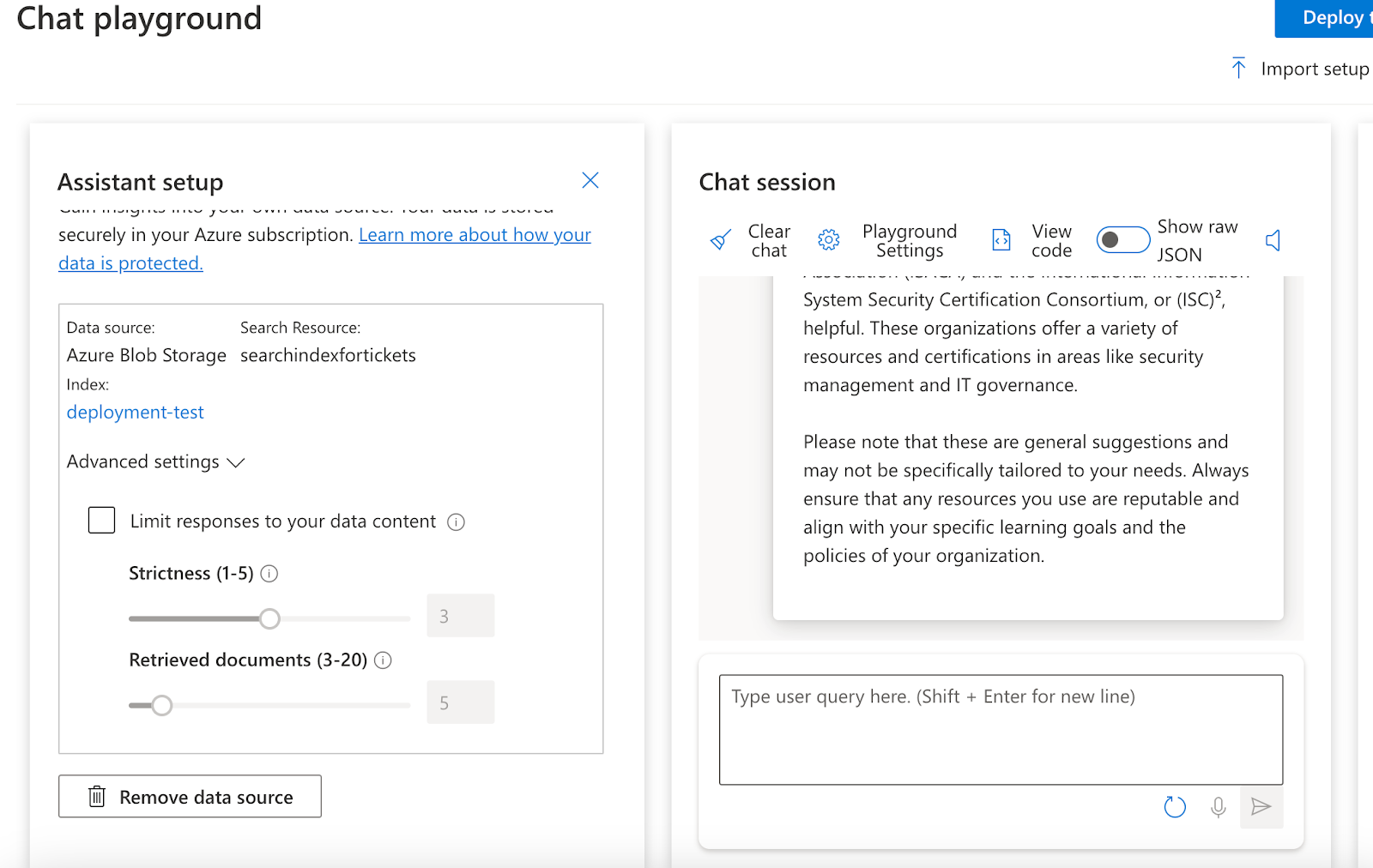
As you can see on the left, there’s a field for our data. This is the public preview feature of bringing your own data to the system. To set this up, you need your data to be in Azure in one of the accepted ways, currently Azure Search (Blob Storage), Azure CosmosDB, or a URL/link to the data. For us, we set up Azure Blob Storage first and a container for the data. Data needs to be in a specific form, I recommend .pdf.
Before being able to use the data, we need it to be indexed and searchable, so we need to deploy the Azure Search service.
In OpenAI Studio, you can’t reuse the search indexes; they need to be rebuilt every time. This becomes an issue for larger data sets, so I recommend you start small and set scheduled indexing in the UI to trigger daily, for example. Then in your production application (more on this later), you set the existing index into use, allowing you to use a larger data set without having to wait eight hours (I learned this the hard way).
The OpenAI Search with your own data does not train the model. As you can see above, it searches against the Azure Search, returns X amount of docs (in the picture above 5), and creates answers based on those documents by inserting them into the model you chose and generating the answer. Note: The picture above shows GPT data set included as a limitation has not been enabled.
This means you want to provide larger files instead of small files, which we will talk about in the section on Jira. For me, this leads to really good answers to specific questions, but wider questions, of course, will not be good as the data set it pulls from is usually really short.
This phase is often referred to as building the RAG or Retrieval Augmented Generation, which was coined by the Facebook AI team where we take the LLM (Large Language Model, for example, ChatGPT’s GPT3.5 or GPT4) model and connect it to a search engine (knowledge base).
The next two phases are called building the KB or knowledge base, which is where we build the search engine data and indexes so the above-mentioned engine can work.
Bringing your own data in from Confluence
So now that we have a way to test and run our AI, how can we bring some meaningful data to analyze?
We want to start getting answers from our own data and building up the information that people are searching for. Confluence was the first place I wanted to have the data. As most of the data in Confluence is quite static, I decided to go with space exports for a quick solution, as I only needed ~10 spaces for my AI to start giving answers.
I uploaded them manually to the Blob Storage in AI for quick PoC, allowing me to get this service running in sub one hour from approval of Microsoft for OpenAI usage. This quick demo was then deployed with ways listed below to test the different approaches.
For production, we will build a proper data pipeline where we will export the data from Confluence via Azure data tooling. This is currently being built and will be a separate blog post later. Confluence currently does not allow space exports in the cloud automatically, so you will not be able to automate it directly but will need a custom solution, such as ScriptRunner for Confluence.
The data format of space export seemed like a really good format for OpenAI usage, so I recommend not uploading pages separately but rather as a larger context of full space exports.
Bringing your own data in from Jira
How would one even start testing Jira data? What do I even need to do? How do I structure it? What’s a fast PoC? I was thinking about these questions as my business case hinged on the Jira data. I did not really understand the data priming I mentioned above that data should be in large scopes.
For me, Python is a familiar language, so I ended up writing a script that fetches all of the issues with a JQL query with my Jira personal access token and pushes them into the Blob Storage. I wrote the script to support .txt storing to Blob Storage, but due to issues with the Cognitive Search, I had trouble with the .txt working, so I wrote another script to convert my .txt to .pdf. This issue, based on my check, should be in order, but as my .pdf data works, I have not verified it with the same data set.
I ended up pushing 60,000 issues to the system, which led to an indexer timeout with default settings, so as described above, index a smaller patch first and set up the indexer timeouts and caches before pushing the mass of the data. This also allows you to store the data in proper order. I recommend running any script on some server or in an Azure function.
My script took me six hours to run against the Jira server. The amount of queries per Jira issue is significant, as you have to fetch the data first by the JQL query, then query the issue details for custom fields and detailed issue information, request for the comments, and in my case, pull the worklog data from Tempo API. Leading to three API queries per ticket overall with my 50 ticket paging, it took me to around 200,000 API requests to Jira per run of the script.
Since working with OpenAI more, I would perhaps change this to be per-project indexing to have wider answers based on a project context rather than an issue context. Issue context ends up with hyper-specific answers, which means the questions to OpenAI have to be just as specific. I have not, however, tested the project scope searching.
To tune the search to your data, you may change the system message to fit better to your AI’s needs. By default, it says: “You are an AI assistant that helps people find information.” This works quite well in these use cases, but by priming it better, you may get improved results. If your AI isn’t working correctly, or you want to tune how it answers, changing this can vastly impact your results (we have seen it change an unusable bot to a working one).
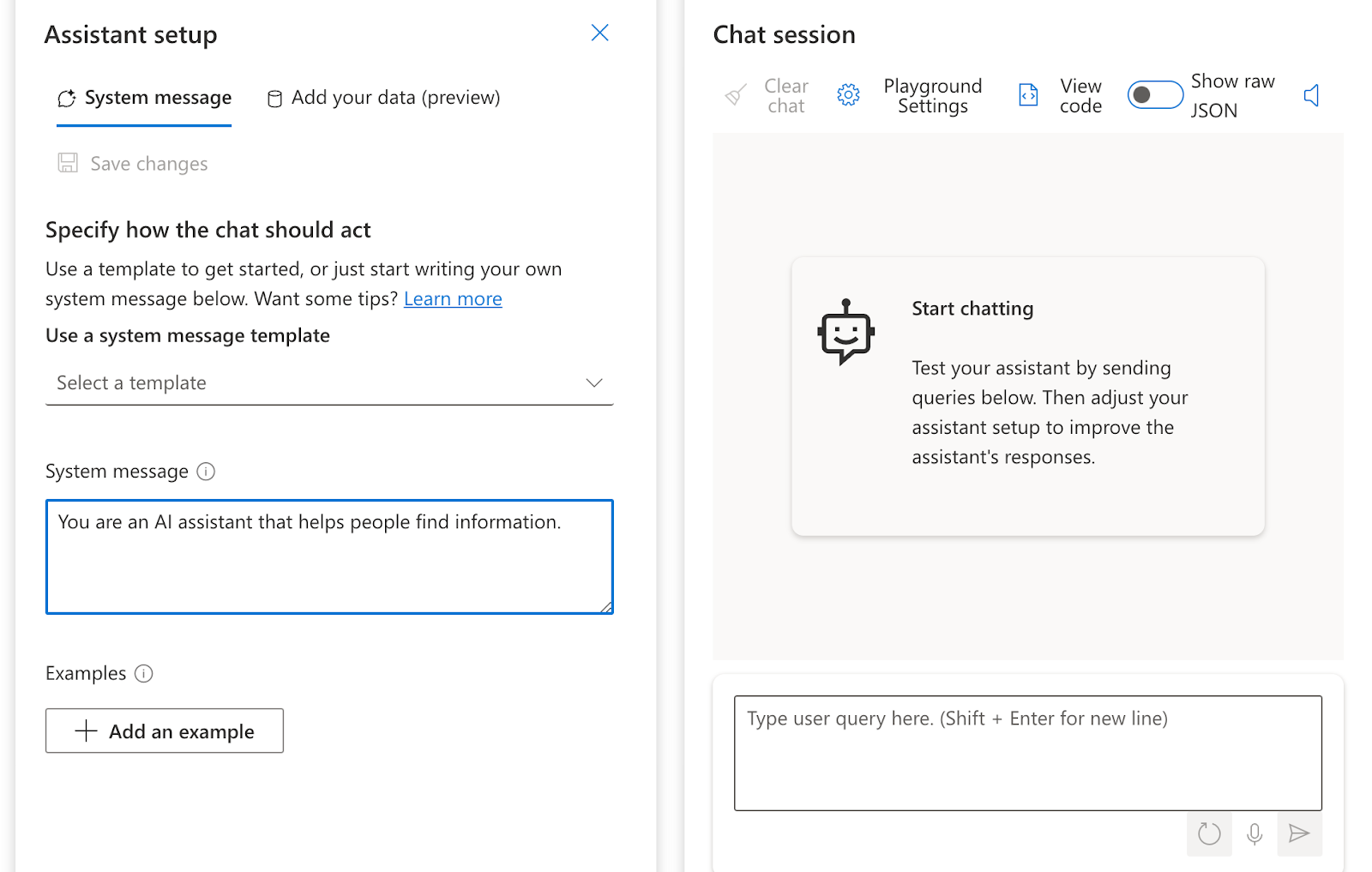
Bringing Azure OpenAI Studio to my audience
Now we have two different chat windows in Azure OpenAI Studio, and I want to start releasing them. I first started by thinking about taking the code from the UI that it auto-generates and building a Slackbot, but my colleague pointed out that maybe Danswer could be a solution as it automatically integrates with Slack and Azure OpenAI.
I quickly took Danswer to work by deploying it to my laptop via their quickstart guide and customized it to use my Azure OpenAI for analysis. The sad part was that where it doesn’t currently support Azure Search as one of the document indexers, I couldn’t use it for my use case. But motivated that the solutions had gotten this far, I thought, “Maybe I should try Microsoft’s quick deploy button.”
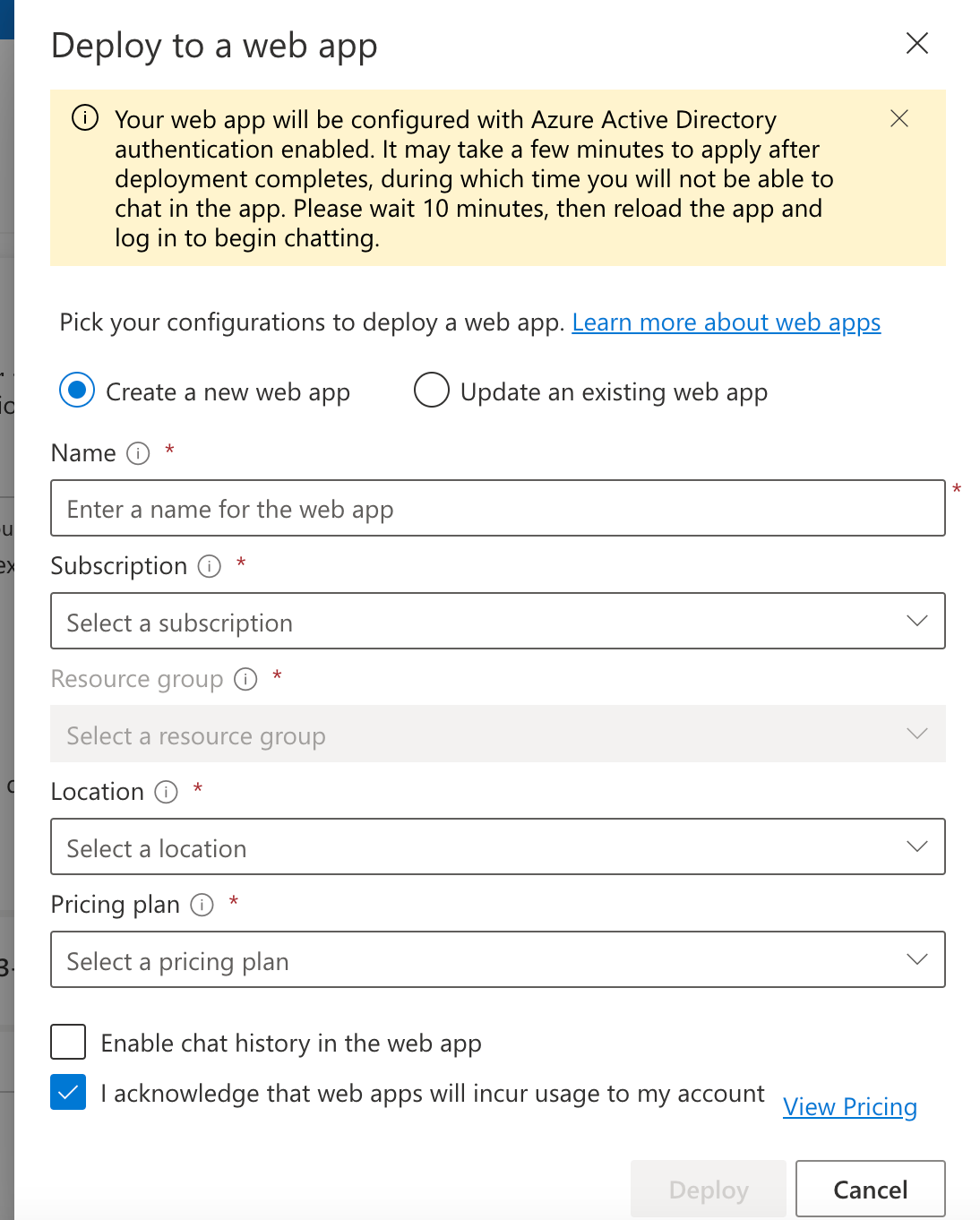
Sadly the bot framework only works for Teams right now, and as we aren’t currently using Teams for our communication, I decided to try the web application deployment, and it ended up being exactly what I was looking for!
You get a super simple deployment form, and after 10-15 minutes, you have a working chat window with Azure AD authentication blocking unauthorized usage and possible controls over who can access the UI.
I ended up with a super quick way to get our end users to test the use cases. (See below for how to deploy the application. Do note the history data requires CosmosDB, meaning ~$5,000/month cost. I recommend for business case building, just interviewing the end users to save money unless you go straight to production to hundreds of people).
Did my business case work?
Well, did it work? To be honest, in my opinion, no, but from an end-user point of view, yes, as they have been happy.
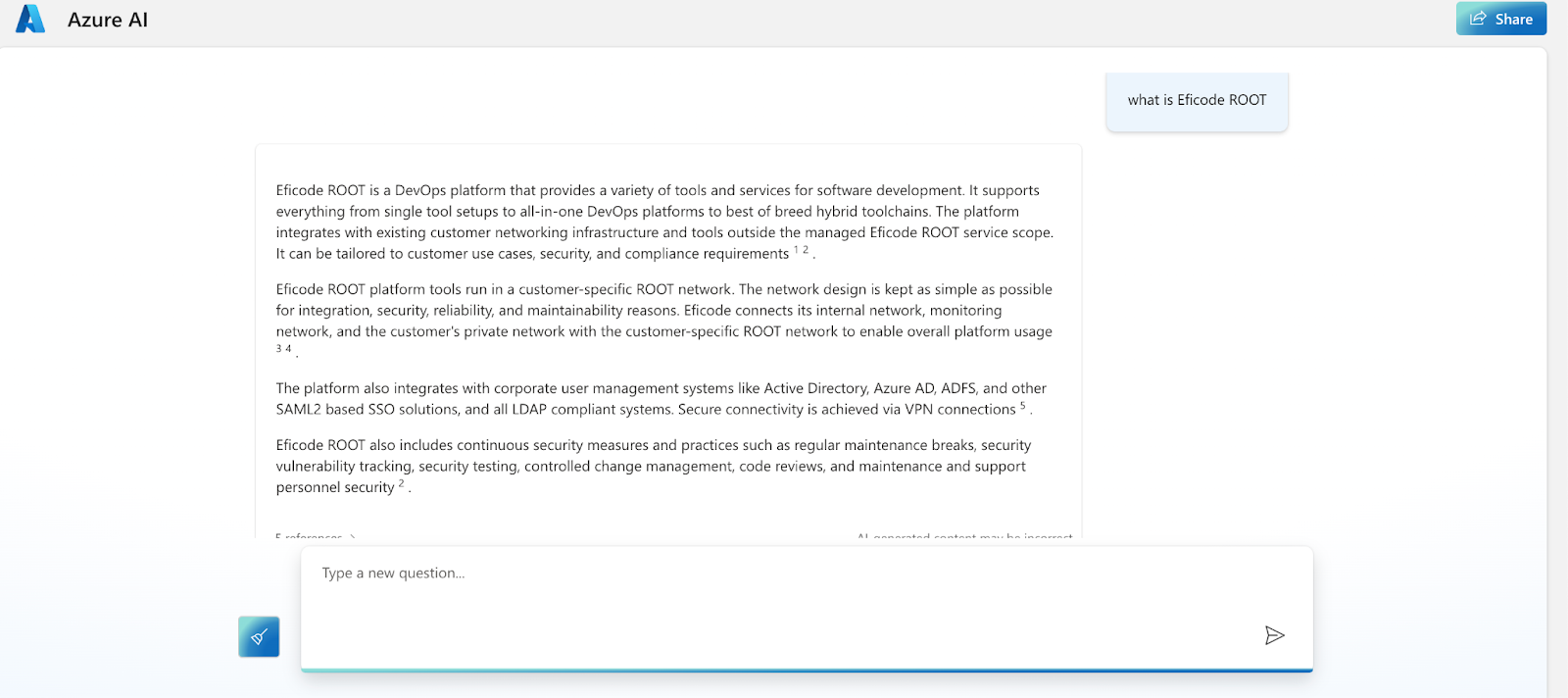
What next? From Azure Entra, I am tracking our logins and usage of the service to understand which of our experts are using it and why. One of our experts took the OpenAI code and is working on integrating it into Jira to classify the issues we see and hopefully create new business solutions for us.
What worked? Azure OpenAI service is quick to get started, and I got to “production” in no time with the web application to test data sets with our experts.
What I hope to work on next: Data format and priming of the data. Based on our quick reviews with experts, it’s good in specific areas but ends up giving false information due to wrongly primed data or assumptions that Azure OpenAI/LLM, for example, Chat GPT creates. But the truth is it’s not a database. It does not aggregate data or analyze it, and it doesn’t create ready-made reports. These are things you have to do from the JQL/database level, as these are data aggregations. It can, however, explain how we answered this issue last time.
Overall I am hopeful and confident that we can create value for our experts and customers long term with this. However, it is not a silver bullet and requires time and focus to understand what we are doing. Happy New Year; hopefully, you feel inspired to try Azure OpenAI with your data.
Published:
Updated:

