A sneak peek of Apache DevLake (Incubating): what it is, and some pros and cons

One of our customers wanted to know my take on Apache DevLake (Incubating). They were considering adding it to their Eficode ROOT stack.
It is a new, exciting tool a lot of people are looking forward to in 2023. I decided to write a brief introduction to the tool with some pros and cons, and share it here on the blog to satisfy a lot of peoples’ curiosity. So here we go.
Let me start by saying that Apache DevLake is not ready for production. The project is clearly in the beginning stages of development in terms of data pipelines. But support for tools is already great, and based on what I saw, it will be a fantastic tool in the future.
First of all:
What is Apache DevLake (Incubating)?
In essence, it is:
- a collection of collectors for data
- transformation tools for the data
- data modeling for DevOps metrics
The analytics currently comes from Grafana. Apache DevLake (Incubating) does add basic dashboards, but I recommend that you currently use the data from the database in your existing analytics tool.
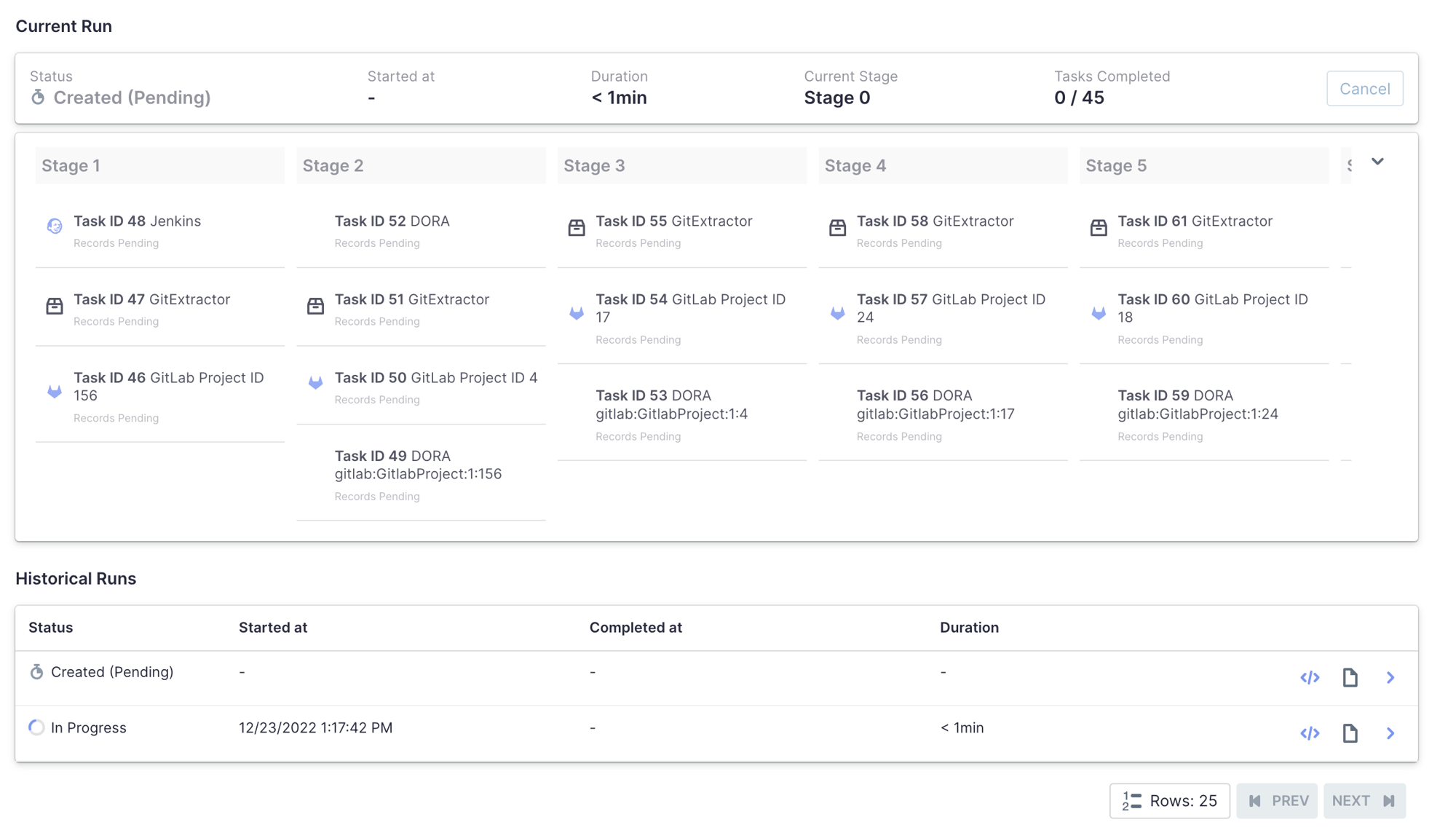
Current configuration of Apache DevLake collector runs for this blog post
The data model is well-documented, so you can easily get started writing your own queries.
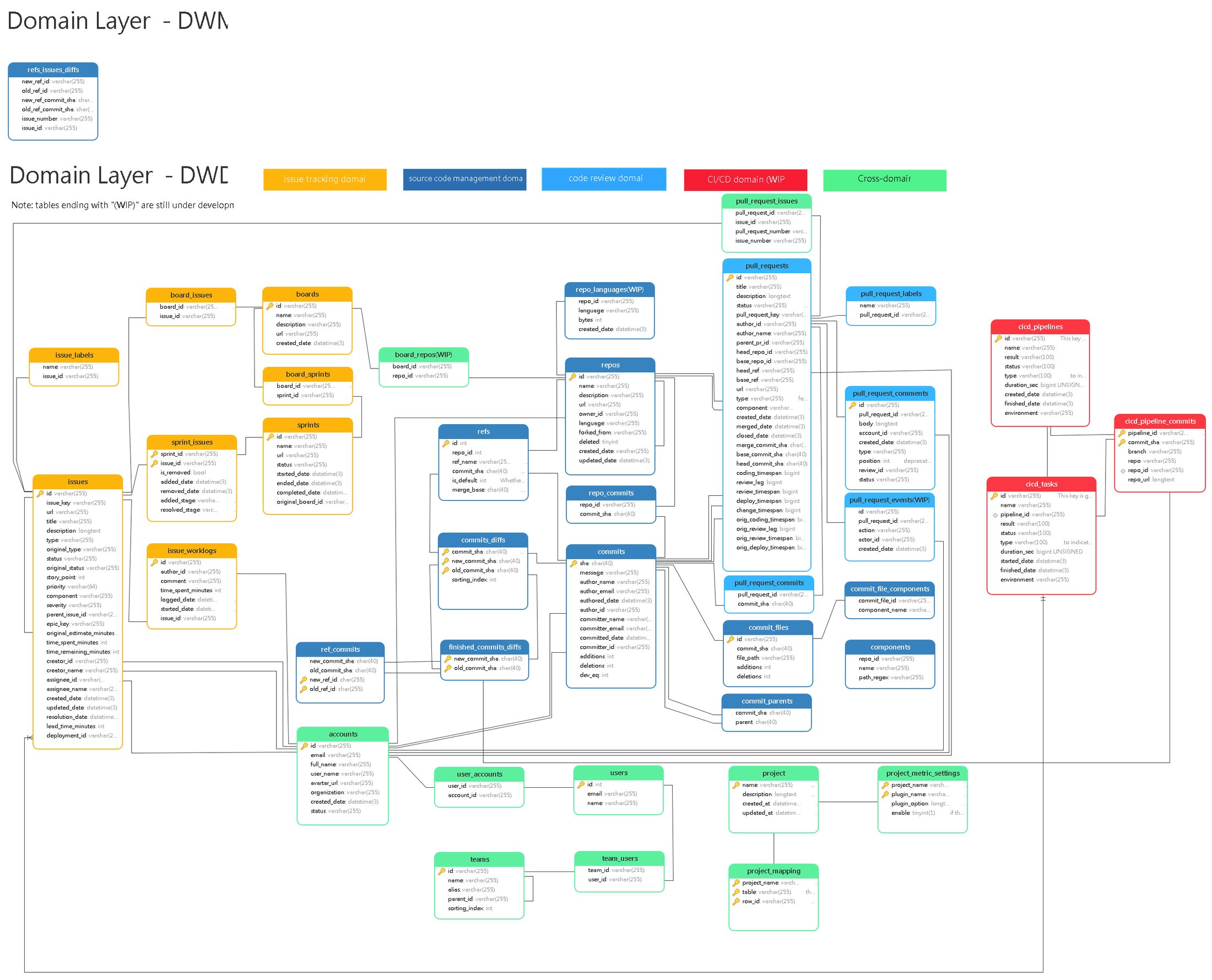
The current database schema
Source: https://devlake.apache.org/assets/images/schema-diagram-320b5e63de6fabd77794a3043a18fa98.png
This enables analytics from the database (which is currently MySQL) with both Grafana and other external tools. The biggest issue here is the fact that you can’t easily use this for multiple instances, and fetching data requires quite a lot of automation around it if you want to do large-scale analytics instead of a single project.
Apache DevLake (Incubating) in itself is nothing new as you can already build the same integrations yourself, for example directly with PowerBI towards Jira.
What is cool with this tool is that you map your Git, CI/CD, and tickets together, so you can run analytics on all that data. When you can connect a feature to a commit, you will see more clearly what it took to get a feature to production, or which issues this feature could have caused.
The pros and cons of Apache DataLake (Incubating)
Pros:
- It integrates with the main Git and issue trackers: GitHub, GitLab, Bitbucket (so far via API), and Jira
- Analytics are by default based on Grafana — easy to use and fast to get started with
- There is an active community developing new features
- Everything is a container so it’s easy to get started
- Written in Go, so very efficient data fetches
- Configs can be defined in JSON
- Fantastic for team project analytics
- Using REST API analytics means it’s super easy to get started with by anyone
- There is a clear, visible roadmap to see what is being worked on
Cons:
- Since analytics are based on Grafana, you can’t perform deeper analytics by default
- Configuring and knowing how to setup the database in a cloud-native way is still missing
- Does not yet give you any information you cannot get by other means
- You have to add projects one by one in UI or API calls
- Data fetching fields are not yet documented and do not support all the features of the tools (Jira and Personal access tokens for example)
- Defining Jenkins pipelines requires mapping to certain patterns, meaning Jenkins jobs need to work in a certain way
- You can’t define higher levels than per-project, so you can’t for example define with Blueprint
- Personal access token privilege levels are not documented and are not the default method
- There is no support for Sonarqube (yet)
- OpsGenie is not coming, but Pagerduty is (can’t use it myself as we use OpsGenie in Eficode)
- Authentication is still missing for collectors (or at least I could not find the setup)
- Many features are shadow-created, so you need to read through a lot of API documentation (this is also a positive as they actively implement features that you can test before they become actual releases)
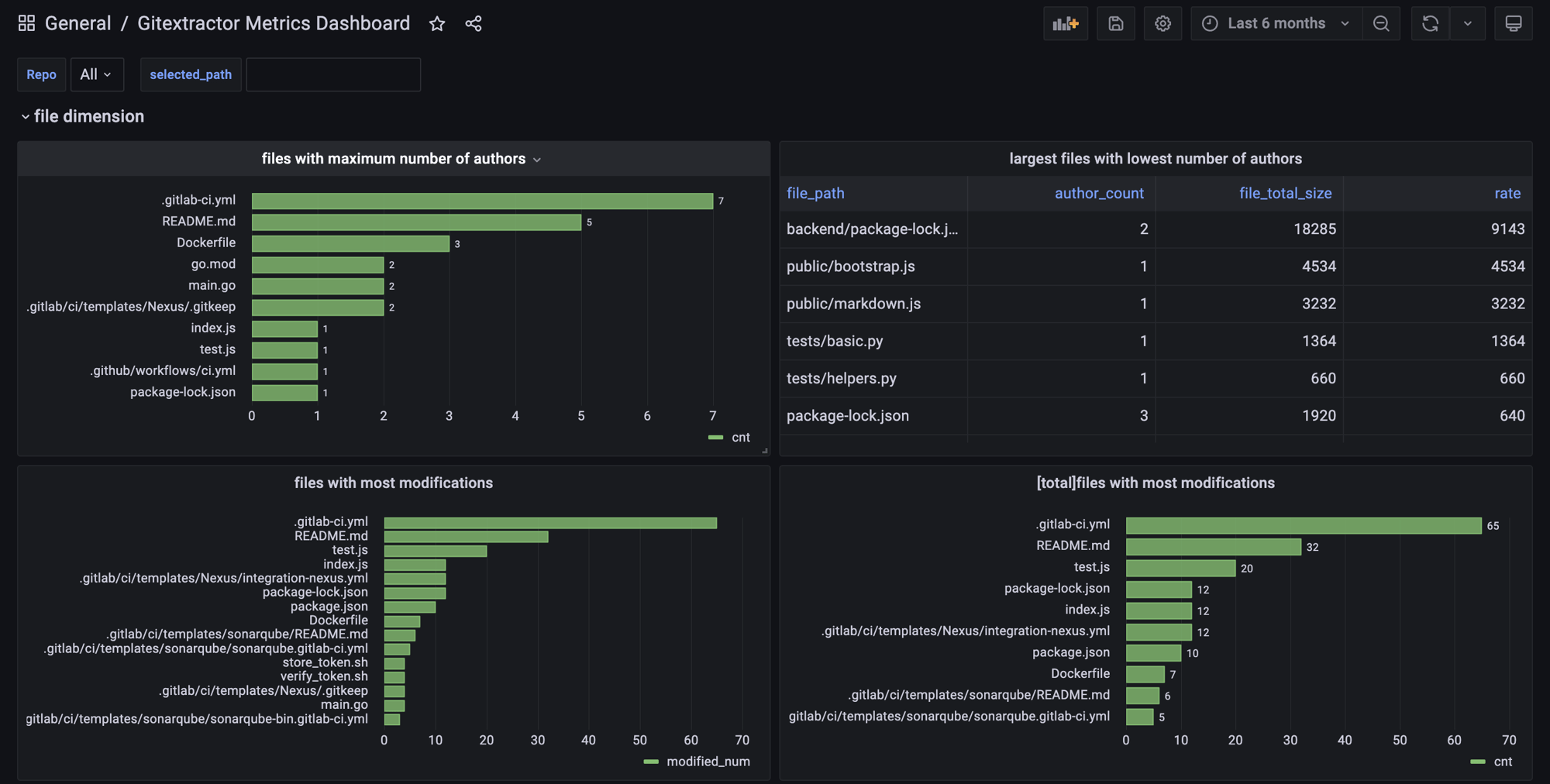 Example of Git analytics from Grafana
Example of Git analytics from Grafana
In summary
Those were my current experiences with Apache DevLake (Incubating). I will definitely keep track of this project, and we are also looking into having beta usage with our managed services customers in future.
It is not quite ready for us to provide it as a service to our customers. But it is a super interesting project, and we are excited about what the team will be able to do with this project.
And even though it may not yet be ready for production use on a large scale, it is definitely something you can test at a team level to see how your metrics move forward. Just don’t promise uptime or data to stay unchanged.
Published:
Updated:


