Migrating to a new DevOps tool: important lessons from the real world

For anyone facing the challenge of migrating from one DevOps toolset to another, I have gathered the most useful lessons, with plenty of real-world examples along the way. Lessons learned the hard way and the easy way, turned into actionable advice.
Table of content:
Are you considering migrating to new DevOps tools? Even if you are not today, maybe one day you are.
There are fantastic all-in-one options available today, like GitHub, GitLab, and Atlassian. But like many, perhaps you feel the whole migration issue is a bit difficult to get your head around.
- What it takes
- How to do it
- Where to even start
Here at Eficode we have started to notice a big shift in customer views:
10 years ago - when we started our Eficode ROOT platform - we had to explain why you would want DevOps.
5 years ago - we had to explain why you should centralize your DevOps tooling.
Today we are here to tell you how to centralize your tooling.
After over 15 years of doing DevOps, we have realized that not everyone understands how hard it is to switch between one CI to another.
We want to give you a better understanding of how to save time and effort when migrating and avoid some of the most common pitfalls. In this blog post, we will share eight valuable things to keep in mind.
Our goal here is not to give complete answers, but rather the questions your organization should ask. The “unknown unknowns”’: what you need to know, to know what you don’t know.
Read on and find the right questions and the contingencies, to plan for a smooth and successful migration.
‘migrations never fail due to technical problems’
1. The culture isn’t ready – yet
Migrations come with technical challenges, but the migrations never fail due to these.
They fail due to people and culture. Many think it’s just a set of tools, but the key problem is managing change. Change management is at the core of every company's culture. Some just do it better than others. So why is this so important? Let’s use a real example.
An example: moving your version control system, Github Enterprise, from on-premise to Cloud
It’s one of the most simple migrations you can make. You have done everything, nothing procedurally changes for the user. Some parts actually happen easier than you thought and you won’t have to worry about your migrated setups. However, every GitHub user has to change one thing in their environment: the URL of the repository. All CI/CD jobs also have this URL.
So what do you do? Rewrite DevOps pipeline logic to support this?
Yes, that can be done (as we have), but how about the hash checks for SSH authentications? Yes, you would think they work, but alas no; you need to go approve those manually.
This will lead to a lot of guiding and pushing the teams. There are probably going to be discussions like: “who pays for the lost time”, “we missed an important milestone”, and so on. You have accrued much bad faith in the organization as you failed in managing the one simple update that required your users to act!
This was just migrating Git repositories. How do you think people who use Jira feel when you want to move them to GitLab?
Tip: When making migrations: map out the integration points so you have a list of affected systems with the URL of the repository to be updated.
To solve this, we usually give our customers the following advice:
Assemble all stakeholders and inform them well before, to provide guidance and business support. Senior staff can explain the “why” of the migration.
- Continuous communication is key throughout – even after the post maintenance phase.
- Business support requires understanding the incentives; migration should be a well-built business case and clear priorities. If your manager asks you “what do we save with this?”, you should be able to actually answer the question
We made a calculator for estimating savings. The calculator is based on Eficode’s experience, and Eficode ROOT solution, but it gives a pretty good view of the stakes.
Because these discussions can be brutal, it is sometimes easier to have an external company doing the migration so you don’t have to shoulder the responsibility alone. We have seen companies sometimes not telling their staff and apologizing after things go wrong, thinking it’s just as effective. However, this is not the best way to communicate with companies and usually leads to worse outcomes than transparency. If it took you longer to arrange the needed meetings than it takes for you to say sorry to those stakeholders, it’s most probably not worth it.
2. People don't like change
Now that we have talked about organizational culture shocks, let’s talk about how the individuals are affected. Strong influencers in the organization pose a challenge. These are usually power-users of these tools who hold strong technical and/or social positions in the organization. They are in love with the tools they use and maintain, and thus see no reason to replace tools they have invested so much time in to set up just right.
You have to make it worth their time to learn the new tool and make their previous experiences count in relation to it.
You need to convert them into advocates and change agents. To do this:
- Figure out who these people are immediately
- Involve them in the earliest phases
- Show them how to solve existing problems in the new tool
- Ask for their advice on where to expand the migration next.
This is a very effective way of recruiting them along to advocate the new tool to the teams. If they understand it, they will embrace it and thus are not afraid of the change; instead, they are your best ambassadors in the migration! Fear of change can often be mitigated by training, and by having discussions with existing users of the tools.
Tip: Get the power-users involved in the decision-making process so they have a chance to explain their views.
An example: Getting to the bottom of Jenkins
One of our customers was very skeptical about whether we could help them in their work and in hosting their tooling. We discussed removing part of their workload, but they thought it was a very low amount of work for them.
We went through how the new tool, Jenkins, works and how they have to check every plugin. If it breaks during the night, they have to wake up and make it work again. We went through the system and the amount of additional work they had to do every day to keep the system running.
What they really wanted was to make a better test architecture for their system instead of daily firefighting and fixing. We discussed how we have previously solved these problems. After that, they asked if we could take a few of their other systems to maintain as well, so they can instead focus on creating and writing code. Being heard was the key step to help them realize where they were before.
3. The focus is not on the right questions
We have found our ambassadors and our culture is warming up towards migration. We should be good to go, right? Let's just tackle those pesky technical issues!
No, not yet. We need to have a clear plan.
We must answer the five questions of migrations that will define our success. This is to get everyone on the same page about the migration goals. We do the same as in software projects: we need to stop and see that everyone understands why we are doing this, and what we are working towards.
What questions to ask during the migration planning:
What kind of migration are we planning?
- What data are we expected to migrate?
- Are we expecting fully hands-off migration for developers or do we expect them to do a lot of changes themselves?
- Are we migrating to another instance of the same tool, or are we migrating to a completely new tool?
- If it's a new tool, what are we expecting to change in the current ways of working?
What are the KPIs for a successful migration?
We need to figure out our KPIs for the successful migration.
- What do we see as success: All users migrated? Teams being satisfied with the new tools? Faster cycle times? Lower costs?
- How do we evaluate these and where do we set the target level?
When you have answered these, you can then ask about the composition of the migration team that is accountable to reach these KPIs. The hardest part of teamwork is to get everyone on the same page. So when you set KPIs, think about how they will affect the different stakeholders.
If you are going for the highest quality, choose KPIs that affect the quality of migration, such as:
- Number of support tickets (with the target being zero)
- Amount of work required from end-users (which should be minimal)
- Impact on business
- Usability of the new system (with a user satisfaction survey).
If you are going for the lowest cost, use KPIs that measure:
- Length of the project
- Feature parity with the previous systems in use
- Tickets that are open after two weeks of migrating.
These affect what the migration team will optimize.
What will the migration team be accountable for?
Now that you know what our migration team will prioritize, it is time to ask: “What should the teams be required to do?” Map this based on your KPIs. If you are going for the lowest cost, the manual work required will be more than if you spend six months developing tools to migrate everyone in one go.
So think hard about what you can expect from your teams.
How do the teams migrate to the new environment?
We often see big-time investments in tasks that the teams could very easily do themselves, and it might even make sense for them to do. For example, moving the CI/CD jobs to the new environment and at the same time cleaning up old clutter.
It usually does not make sense to migrate something that won’t be used, especially if it never even worked as the team expected. But sometimes teams want their CI/CD to be moved in one go. They don’t want to mess with a thing that works.
So ask yourselves how to reward and build pressure for teams to migrate. "This service will close in six months” is always a valid stick, but is it effective in our organization?
I have seen many organizations that inform their users that service will be terminated, but because the people know that the termination will not happen, people continue using the old solutions. The teams may even be using environments that were “killed” decades ago.
If you want to bring the pain back: move the cost to the teams still using it. Usually, at that point the team migrates surprisingly quickly to a new system. But also remember that every organization is different.
Okay, so you have KPIs, requirements, and the specifications of migration. But you still have the hardest question to tackle. One that you are most likely not able to answer by yourself, and your superior wants to avoid like the plague. But if you don’t solve it, you will throw sand on your ice slide.
How do we distribute the costs?
You have the direct cost of migration, like licenses and work spent on it. That’s clear.
But what about the indirect costs and opportunity costs? Both will affect the above; this is why the specification was created in the first place. This is needed to prevent someone from blocking the migration.
You need to have a clear plan on how to inform any team that this project needs to happen. Or you have to allocate the needed cost to the migration team if delays happen due to these costs. Who will pay for the precious development time you didn’t do while migrating? There should be a clear answer and it needs to be supported by the whole management team, or at least your sponsor needs to understand this question is coming their way. By informing everyone before they have a chance to ask the question, your stakeholders will have a better impression of you.
An example: a full migration
In a successful migration, I made a few years ago, the customer said “we want a full migration so we don’t have to do anything”. And that’s what we did:
- We prepared scripts to update the git repositories with new URLs
- We made Artifactory URL redirects automatically replaced with new safe ones
- We made the migration of jobs from on-premise CI/CD to the Cloud, tested them and prepared them to run as they did previously, and also prepared their Jira and Confluence migration from Oracle databases to Postgresql
- While at it, we moved the whole infrastructure to AWS.
The cost of this work was much bigger than the customer expected, as a lot of environment-specific code had to be rewritten to provide URL redirects to prevent things from breaking, but at the same time convert all traffic from http://address:port to https://service. It was a small customer so we expected that they did not have the time. But after listening to the feedback on what went wrong, they said:
“We could have changed those URLs ourselves. It would have been very fast for our developers as part of their normal work”. So by failing to specify the “what will the teams do?”, we ended up doing far more work than the customer expected. Today, they are still a happy customer with trust in us, but we learnt our lesson. We now always guide our customers to specify the important parts they want us to solve for them, so they also have a budget for these.
Just to recap our questions for the migration:
- What kind of migration are we planning?
- What are the KPIs for a successful migration?
- What will the migration team be accountable for?
- What exactly do we want the teams to migrate? Are there any incentives for (or against) the migration?
- How do we distribute the costs? All three of them: direct, indirect, and opportunity costs.
4. You need to drastically reconfigure
Whenever you change the tool you are using, the configurations can drastically change: the tools work in very different ways. So in the planning phase, always define “what can we lose?”; not everything will be easy to implement again. You can usually implement many of the features, but it may require lots of work compared to the benefit of that feature.
For example, you usually can’t replicate permission levels exactly, as some tools have far more fine-grained permission levels and roles than others. You have to map which permissions go where and what permissions teams need by default – all beforehand.
With CI/CD, there is no one way to build or deploy in any organizations I have come across. I have even seen organizations that offer ready-made deployment jobs but still see differences between teams.
Tip: write a general overview of what you have. Figure out how many of those jobs are defined with code and how many are defined with an UI, (if the tool supports UI configuration of a job).
Most likely you are migrating to a tool that only supports as-a-code, or you want to migrate all jobs to code. So it’s important to figure how many of these are about just switching the syntax and where you need to teach the team completely new ways of working, as they need to learn that the CI/CD belongs to the repository.
Prepare good articles for the top languages and use cases with the ambassadors you have. And get ready for the yet unknown challenges of mass migration, where you will learn how even the simplest configuration change can face turbulent waters.
An example: Running a Jenkinsfile parser on GitLab
Imagine a scenario: you have everything in Jenkins jobs and you will move to GitLab using Jenkinsfile parser to have GitLab run the Jenkinsfiles on the same servers with the same configuration. Things will still break, as stuff won’t work for every situation. For example, a lot of jobs in history were built by sending binary to Jenkins master.
If such a binary deployment is in use and you don’t have the binary anywhere else, the future setup with GitLab will be incredibly hard to implement. This is due to the different way binaries move between jobs. As a result, some jobs require a complete overhaul. If they are a chain of jobs that work together, they would need to be re-engineered into one pipeline, which might prove challenging, since there are usually reasons for the original design.
Learn how to work with the new tools first and then reflect on what should be done, rather than going overboard during the migration. You will not cover all the scenarios, so rather focus on the masses instead of trying to cover all the complex scenarios.
You usually want to make sure 80% of the people will have a good time. As for the rest: well, that is why you did the first three steps – so you can sail through the murky waters without drowning.
Our top tip for this is: do not go overboard, just make general assumptions and prepare to fix the rest after the migration.
5. Should you automate or guide people?
You now have mapped out the differences between tools and have procured the tools for your organization. Now it’s time to tackle the next big question: how much to automate and how much to guide people? The guiding principle should be: how to impact the work correctly.
So, ask the following questions:
- What data or functionality do you need to bring to the new system with you?
- What data or functionality can you consider as an option/additonal goal?
- Which new features do you enable in the new tool by default? Were these features in the old environment?
Now that you know what needs to be done and who is doing it, it’s time to start cracking on with the actual implementation backlog. What you want to automate, and what you want to establish guidelines for, depends on how widely used the feature in the tool is. And also, how much time it would take the teams to take it into use. You should also think if there are regulations that would require those features to be in place.
XKCD has put together a great illustration highlighting how long can people spend time making route tasks more efficient, and still save time across five years.
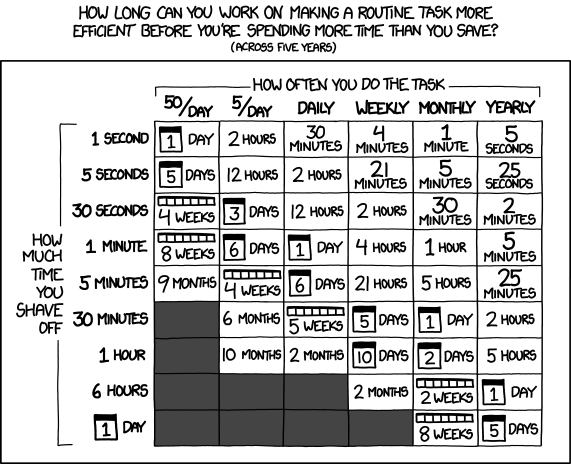
Source: https://xkcd.com/1205/ Is it worth the time?
In a 6000-developer organization, even the smallest automation can save a massive number of hours, such as not breaking URLs and backward compatibility, or having CI pipelines automatically have certain things implemented in them.
The larger you can go, the more time you will save. For example, changing a Git URL in that 6000-developer organization might be a 10-minute job, but then it takes 60 000 minutes for the employees, theoretically leading to an extra work of 1000 hours.
Truth is, most likely it’s done while thinking of another task or while still reading morning emails. But just 10% of those hours in productivity would be 100 hours of lost work time. Therefore, automating things that affect everyone is usually the smart bet.
Branching strategies and merging strategies in Git are another thing that would directly affect your employees. So you would not like to use the wrong ones in every project. Therefore, consider:
- How the automation will affect the end-user
- Where and who would use the built automation
- How to make sure the correct settings get replicated to projects
It’s also very important to understand what you can automate from the CI/CD agent, runner, or action. Ask:
- What kind of customization do we allow?
- How do we enable it?
- Who will manage it in the future?
- Where is the point when the teams have maximum benefits, but for example, not all regulations have to be in place yet.
- Do we host these for the teams or do the teams host themselves?
We usually recommend that the expertise of hosting these should be purchased from a professional service, as the agents/runners/actions are often a source of surprises. This means changing these at all during migration almost always leads to challenges.
An example:
On Windows using C#, you can authenticate with the AD permissions to the SQL Server database. For this, the server needs to:
- be connected to AD, with hard-to-automate redeployments
- have access to said credentials, leading to security concerns about how who has access to the agents/runners/actions
These are things that can be sorted out and worked through with the team beforehand. Perhaps the agent/runners/actions need to stay and be maintained manually by the team during the migration, rather than moving to an autoscaling and auto-maintained cloud environment, due to the complexities involved.
Don’t try to fix these pools during migration (this is impossible). Aim to keep the system as similar as possible for the first mass migrations and concentrate on them after. It takes additional work but it saves time overall.
Sometimes we think that automation has solved our issues, but in reality, things are never so straightforward. Consider a statement: We have all our environments containerized and documented already, why would we need to care?
This likely means you have a chance of moving to a centrally managed agent platform, like running things in a unified Kubernetes environment for all teams. But this also means that networking still needs to be planned and prepared.
Converting things to Kubernetes without mapping the old environment requirements, even if they were dockerized, is risky. If you go to centralized run Kubernetes agent pools, make sure to deploy them to the cloud when possible.
Hosting and on-premises Kubernetes for the sake of build and deployment is very expensive, and you can’t build similar scaling as in the cloud. To clean up the cost and faultiness within the environment, you constantly want to ramp down the underlying infrastructure.
Automation is your friend, but automating everything is not always worth it. Focus on the critical things that we specified before. Think “will our users really need this or could they manage this themselves?”. If you still feel it is needed, definitely look into automating it.
6. Consider how you migrate artifacts
Swapping an artifact management software sounds like an easy thing at first. But migrating those binaries is often a lot of work, due to many different interconnected things. You have to map which repository types you have in use if any.
Many CI/CDs allow you to use their own disk for these temporarily. This often leads to problems in migration due to the binary not being stored how you expected it to be. And if you for example move from static agents to dynamic, that destroy the disk between every build to keep the clutter from forming up, you could be in trouble.
This means that migrating these binaries is risky. It’s not enough to check that the new systems support x,y,z technologies but rather “does it also support remotes + virtuals”?. This means that you can easily build a remote repository connection, for example to npm.org, and connect it to your other repositories via virtual repositories.
Ask this:
- How about the layouts of binaries? These are also customizable in many tools.
- Have you been using releases in the binary system?
- How will you use those in the future system?
There are surprisingly many things to figure out before starting the migration and if the tool supports the necessary features.
URL changes
Any changes you make to the binary URL or where it deploys will affect all of the jobs that use the binary repository you have defined. Changing the URL will affect all jobs using said binary. This means we need to search and replace URLs, or magically map them in the proxies, to make sure the binaries can be accessed as before. In the past, our team has had a lot of trouble removing ports and adding https to the artifacts, as those are standard security features to any current-day system (but enforcing them so that CI/CD still keeps working is not easy).
DevSecOps pipelines
How about your DevSecOps pipelines? How do they integrate to the new tool? For example, Jfrog Xray only works with Jfrog Artifactory, which means you now need to swap your DevSecOps tool for another. So it is no longer about changing one tool, but many tools.
While working on that, you also need to figure out what remote repositories you should offer, as many teams might be using public internet directly, for various reasons. So you should aim to offer them lower latency availability from your binary management system.
Binary storages
Binary storage is not just fancier shared disks. They have a lot of amazing features that could become an issue if you for example want to migrate to GitLab completely (as many of the features are not yet available in the tool itself).
There are options for this, such as archiving the old stuff to save costs and just fixing things when problems arise. Or moving to the new system while keeping the old one, starting to use the new features bit by bit and seeing which features you still need. Depending on the needed features, you may be able to do some other magic to get rid of the pricey system you have been hosting for the developers.
An example, opting for a Docker remote proxy
One of our customers decided to move everything to GitLab, and remove all other solutions from their pipelines. This meant extensive research on how to offer binaries from GitLab and restrictions. We concluded that their teams were heavy users of Docker, and needed a docker proxy.
Our solution was to follow GitLab’s guidance, and have a docker remote proxy for Docker Hub, to use the images with GitLab without paying the license for the old system. Doing this, they made small savings on their DevOps costs.
I can’t really call it a success, as the savings were very small, compared to the cost of the project to migrate the binary management to GitLab only. It will take them years to save the money back from this change. Therefore I often suggest:
- keep the binary management software and maybe just move it to the cloud
- integrate it to S3 buckets or comparable, to have cheap disks for it
- move to a more optimized architecture for your binary management
Costs can be lowered more easily in other areas, than binary management licenses, which cost quite little due to competition in that area.
7. Legacy pipelines
You are now finally ready to start thinking of moving your legacy to new systems, and making the team work with the new tools. You have gotten through the politics and changes to the way of working and are finally ready to ask:
How do we move the old tools to the new system?
We often hear about teams moving from Jenkins or Teamcity to GitLab or GitHub due to the single platform benefits. They are looking for silver bullets for this. The first thing we check with them is “are you using jenkinsfiles or Teamcity YAML?”. The answer is typically: “some of our teams are”.
This means we have handmade ClickOPS jobs that we would need to rewrite to any of these tools. The jobs were made when CI as a Code was still a prominent concept, but not implemented yet. Therefore the handmade artisan pipelines need to be rewritten completely since there is no easy way to migrate them to the pipeline model.
Next, prepare a list of:
- what you need to change in the jobs to make them work
- what the new syntax looks like
- how Maven, NPM, Nuget, or other package managers works in the new tool
You need to make demos, examples, and documentation for the team during the migration. This will help them rewrite and fix their jobs when something starts going wrong.
You may be able to replatform some jobs by building hacks, such as running a Jenkins core in an agent, that enables you to run Jenkinsfiles in a GitLab runner. It is mostly only usable to get masses migrated, and should be thought of as a temporary solution and to encourage teams to rewrite the job.
Rewriting is needed for the SAST and DAST capability enablement. And if you do not build such parts into the job:
Why are you replatforming everything? If you are not trying to benefit from new parts of the DevOps communities’ accomplishments, what are you trying to achieve?
Let’s return back to the beginning of this blog: if you have no intention of replatforming, do you really have a business case, or are you just changing due to the need for change?
Migrating tools often involves the need to replatform and refactor for the new features. But also because none of the tools use similar syntax, so migrating to and out of the product is very expensive work. That is why many companies shy away from it. The end result is usually worth it: after the migration, you can easily start moving people across tools and products, as teams are working in the same tools and processes.
When migrating, you need to plan how to manage and help in exceptions, and how to monitor the way forward and keep the systems up and running for your teams. Usually, migrations require very strict project management, and also the monitoring of:
- Who is still running their jobs and why?
- What do we need to solve?
Some teams will say that a feature is missing, or the way it is implemented is a blocker for them. There are many ways to build a pipeline and none of them should be writing a groovy script with 400 lines of code just to solve a process problem.
Don’t try to solve everything with the CI/CD, but rather by building a culture of trust. If you can’t trust your work and steps: stop and look at what you are working on and how. If you are not ready to trust your pipelines and ways of working, what can you trust in your DevOps?
Start by discussing the feature with the team and ask the question “why”.
- Why are we not trusting our tests?
- Why does this need human interaction?
Enforce that the team should be trusted. If not: you are not doing DevOps.
If you are doing CI/CD to speed up deployments, let those teams stay in that tool. They will not change, regardless of what tools you set them up with. Move the git repository and leave the CI/CD there. Changing the build tool for the sake of changing the team rarely works.
But if they are ready to change and embrace the trust you show them, it’s time to trust them. They will manage.
8. You need new dashboards and views
First of all, forget about migrating your dashboard and views. They will not work in the new tool as they did in the old one. Remake them to fit the new tool. And during the migration, consider things like: “do we really need this dashboard that shows green or red, or can we make it into something more usable for remote working?”
Dashboards can only show what you tell them to show, with the data you give them. You can’t show a view of data that you don’t have. Your team needs to implement the dataflows, so consider why you want each dashboard.
Dashboards are a two-edged sword. If your teams focus on improving the dashboard’s numbers, you risk having the dashboard making your decisions for you.
For example, at one customer we started to measure releases in Jira. Shortly after, we implemented automatic release creation and closing for the team, based on tickets moved to Done in a period, enabling them to show their releases in the metric without having to actually use the feature. This boosted the metric 10-fold, but it did not really solve anything for the team.
Another bad thing about dashboards is that if the team does not care about the dashboard, they won’t look at it. So instead of turning everything into a dashboard, stop and think “what do we really need?”. “What are we trying to accomplish with this?”
Data is also just as good as your parsing for it. “Garbage in, Garbage out”, as they say. Anytime you make a dashboard “quickly” with data, you might be leading the team astray.
For example, I have seen customers do A/B testing where they mixed up sessions with users, thus ruining the tests with massive amounts of data points, rather than using selective grouping to determine if it was a useful feature or not.
Compliance and application lifecycle metrics often span across teams, which is a whole other area for optimization. We normally look into these at each phase of migration, from pre-planning to sustainability.
To measure the success of your migration, do not use traditional software development lifecycle metrics. They are deceitful so long as your coverage is not there. Use metrics that measure adoption.
For example, some of our customers thought they were doing well in terms of DevOps tooling, but when we started researching their DevOps usage, they only had the version control part in use in the stack. So they were barely doing DevOps, and were focusing on the wrong things to push their tooling forward. Their metrics told them they were doing well: that they were using the tool. Which was technically true, but you need to use metrics to support the team and ways of working in the tool, not the product usage.
A few parting words
Working on this post has been a fun experience of trying to summarize the ever-eluding migration of dreams. Here are a few last words of advice.
It may not be pretty
I have managed a few times to do fantastic migrations, but I would say that it is very rare. Usually they get very messy even with all the knowledge I have gathered in the last 10 years of doing these for DevOps tools and cloud. Every time there is a surprise waiting for you behind the requirements management process, which you are there fixing alone at 1 AM on Saturday night, knowing that testing starts tomorrow morning and if it's not ready by 10 AM, the whole migration gets postponed and you have to go through the last 36 hours of hell again. So you keep pushing, hoping to solve it.
Don't be afraid of failure
Sometimes you succeed, more often you fail. When migrating, don't be afraid of failure. Embrace the learnings of it and prepare better for the next time and try to avoid having over 40 hour migration days. They are not healthy and they are really not productive. Agree with a coworker, have good handovers, and aim to have a team with fresh minds.
An example of a migration that went well
To round off, I want to tell you about a migration that went well.
We went to the meeting and the customer said they were migrating in the next month. It needed to go well, as the old provider would stop supporting the software in 1.5 months. We made a plan for the product (which we know well), prepared the environments and data migrations, and made sure everything was prepared. We ran a multitude of test migrations and checked that everything went well.
On a go-live day, we began our migration, and the DNS was migrated as agreed. But the TTL was set to 1 hour, leading to the migration lasting 1,5 hours, due to an oversight in the DNS. There were no other problems whatsoever, and we were in production as intended. Even after all the experience and training, one oversight can triple such a project. It went well and we were happy to be in production.
Just remember: try to enjoy the stressful trip and celebrate the success. I will now head for a beer and celebrate the migration of this data from my head to paper.
Published:
Updated:
