How to successfully migrate from Redmine to Jira

1. Why migrate from Redmine to Jira?
Jira has some advantages over Redmine which are also highlighted in Atlassian’s own comparison of the two tools:
- Jira fully supports Scrum and includes boards and statistics for the sprints. Sprints can last for an arbitrary number of weeks and it’s easy to see the workload of each team member in each sprint.
- Workflows can be easily customized to suit the company’s requirements, e.g., that an issue needs to go through all the different stages before it can be closed. Unlike Redmine, with Jira it’s also possible to configure a workflow for a specific project. In Redmine, the workflow and statuses are shared globally among all projects.
- Workflows support validators, conditions, and post-functions that can be used to automate the processes. The standard installation of Jira has some options for conditions that can be applied to a workflow.
- Boards showing the statuses of issues can be customized in great detail. In Jira, it’s possible to configure queries that are convenient for the daily scrum stand-ups, so it’s easy to see what individuals have been working on the day before. With Redmine, these filters need to be set up every day.
- Field configuration schemes are quite flexible and can be used to customize which fields are mandatory in a particular project and for certain issue types.
Redmine does not fully support Scrum, and it is more targeted towards a Kanban style of working. In Redmine there are no epics, but stories, bugs, and sub-tasks. Jira includes epics, stories, sub-tasks, and bugs.
In addition, Jira has two board types, one for working Scrum and one for working Kanban. Those two boards can be configured with queries to avoid repeating common searches.
Redmine has a couple of advantages
Redmine provides a time tracking module that has more granularity than what Jira offers out of the box. In Redmine, there’s an additional activity field in addition to the time spent and comment fields in Jira.
Redmine is also open-source software, so it does not require licenses. This is a potential reason for staying with Redmine because it’s still an actively maintained project.
2. Exporting and converting data.
To move from Redmine to Jira all the current work needs to be migrated from one system to the other. The steps involved in the migration are:
- Export the data
- Convert the data
- Import the data
- Adjust the presentation in Jira
There are a couple of ways to do this migration, but whichever method is chosen the presentation step should be much the same.
Pre Jira 8.4
Up to and including Jira 8.3, Atlassian offers import from different third-party tools such as Redmine, Trac or Trello. These tools are bundled with the default installation of Jira. That option essentially takes care of the three first steps in the migration mentioned above.
After inserting the credentials there are prompts for which projects should be imported and in which Jira projects, how custom fields should be mapped, and how links should be created.
Unfortunately, Atlassian ended support of the automatic import plugins as of Jira 8.4, which means that it’s only possible to import using either CSV or JSON.
We chose to use the automated tools. The importer takes care of things that would require more considerations when importing JSON, but it is also less flexible.
When creating a project in Jira a project template has to be chosen that describes the workflow and available statuses. For migration purposes we used a dedicated project template to describe statuses from Redmine in Jira.
Redmine projects had more statuses to choose between than the default project templates offered in Jira. Therefore we needed to adjust Jira to reflect the statuses from Redmine.
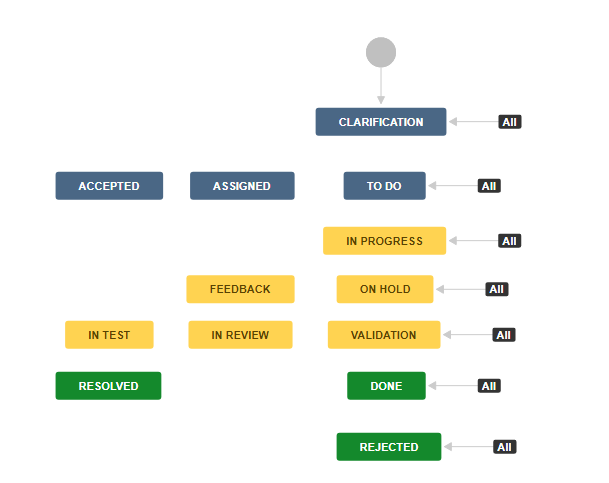
In our case, we needed to adjust a project template to have an accurate mapping of the statuses. The project templates can be adjusted to include statuses that cannot be transitioned to, but will be needed for the post-processing so teams can individually choose which status tickets should be moved to. Multiple statuses in Redmine could map to one status in Jira, but since that would mean making assumptions on behalf of others, we decided that some statuses should stay temporarily. There are some statuses in yellow that are used for the same thing. It may be that tickets In Test should actually be In Progress and if so it’s easy to bulk move them. That would be impossible if you made assumptions during the import.
Issues with the importer
Every time you import a new project a new custom field is created that makes a mapping of the old system to Jira. This field is used to guard against re-importing the same issues again. But it also means that some additional merging of those fields needs to be done. ScriptRunner offers a feature where, based on a predefined filter, it’s possible to merge such fields into a single custom field. The list of custom fields increases the more projects you import, so it’s easy to lose the overview. In Jira, you can customize how the data of issues is represented, so limiting this to a single field will also make it easier to customize the screen. It also makes it easy to send out instructions on how to search for old issues to affected teams. Note that when adding a field to a view screen, the name and value are only shown when there’s a value.
The resolution statuses were not mapped correctly. We ended up getting a resolution status “1” into Jira from the migration tool that doesn’t describe how the issue was resolved. The client did not care too much about the old issues that had already been resolved, so the resolution status was removed as an option from the resolution screen. This meant that new tickets would not be resolved using the meaningless resolution status. In a workflow, there are some properties that can be set for a transition which impacts the resolution screen. In effect, the projects still have this odd resolution status, but new tickets will not be able to set the resolution status to this value.
The issues numbers, e.g., PROJ-1234 that the importer assigns are random, so increasing issue numbers does not reflect the date of creation of an issue.
The importer tool does not import all relevant data. For the projects in Redmine that had sub-projects, we created a component in Jira with the same name as the sub-project in Redmine. Components in Jira are more flexible than sub-projects in Redmine as they have the option of having a default assignee of issues. In our case, we needed to set the value for Story points, the fixed versions (also known as the release) for issues, as well as the component for projects with sub-projects. We just iterated over a list of relevant parameters and then made REST API calls for each of the issues. The netrc file contains credentials for authenticating the user against Jira.
curl -X PUT --silent --netrc-file ~/.netrc --url "${Jira_URL}/rest/api/2/issue/${jira_id}" --data @./${jira_id}.json -H "Content-Type: application/json" {"update":{"components":[{"add":{"name":"abc"}}],"fixVersions":[{"add": {"name":"abc"}}]},"fields":{"customfield_10006":5}}
In Jira, there are a number of custom fields that can be set if the context has been configured for a project. The custom field 10006 is for story points. The IDs of the custom fields can be found in Jira admin. Please note that if you are planning on using other custom fields in Jira for your migration, you need to configure a context for that field to set it for a project. If you do not the REST API call will fail with a warning that the field can’t be set for the issue.
Jira 8.4 and up
Atlassian announced that the importer plugins are no longer available as of Jira 8.4. However, it will still be possible to import JSON or CSV files. This will obviously be more work, as all the relevant data needs to be extracted through the REST API of the tool that you are migrating away from. Some tools may not expose a REST API, or the REST entry points do not expose all the data you’re interested in retrieving. If you are on Jira 8.4 or above, and would like to migrate from an old system, Atlassian has detailed documentation about the format that can be used for import. CSV is most likely only a good choice if the data set is quite small and contains only very basic information about the issues. CSV is much less verbose than JSON because there’s only one line per issue. With JSON, it’s easier to review and query the data with something like jq, making manipulation and inspection much easier.
Redmine has a REST API that supports extraction of the necessary data. This covers users, issues with metadata (comments, relations, releases), and projects. Some data cannot be extracted with the REST API, e.g., the dates of the releases for a project, and need to be extracted manually from Redmine’s interface.
We did not have a ready-made conversion script. However, we needed to write some Python code to output JSON to import the sub-task links correctly, and augmenting this to include users, projects and issues - including attachments - appears to be manageable. We discard the copied_to links because they had already been handled by the importer plugin.
def read_children(redmine_id):
# Extract all the relations (clones, children/sub-tasks etc.) from a Redmine issue
response = requests.get(
url="{}/issues/{}.json".format(redmine_url, redmine_id),
params={'include': 'relations'},
)
try:
return json.loads(response.text)['issue']['relations']
except (KeyError, json.decoder.JSONDecodeError) as e:
# some issues may not have any relations
return None
def main():
parser = argparse.ArgumentParser()
parser.add_argument('key', type=str, help="Project key from Jira project")
args = parser.parse_args()
links = {"projects": [
{
"name": "Project",
"key": args.key.upper()
}],
"links": []
}
# a CSV file from Redmine with all issues that could have sub-tasks relations
# is needed. We hardcoded the filename as proj_issues_links.csv
# The script will just crash with a FileNotFoundError when the file is not
# there
with open(f'{args.key.lower()}_issues_links.csv', mode='r') as f:
reader = csv.DictReader(f, fieldnames=[
'redmine_id', 'tracker'
], delimiter=';', quoting=csv.QUOTE_NONE)
for row in reader:
children = read_children(row['redmine_id'])
if children is None:
continue
for child in children:
if child['relation_type'] == 'copied_to':
continue
linktype = child['relation_type'].capitalize()
links["links"].append({
"name": linktype,
"sourceId": child['id'],
"destinationId": f"{row['redmine_id']}",
})
with open('import.json', 'w') as fp:
json.dump(links, fp)
The script uses f-strings introduced in Python 3.6. The script can be invoked using:python import-links.py <Jira project key>
Adjusting the presentation in Jira
Although we chose to import and convert the data using the importer plugins, there are things that need to be considered after the migration. In Jira, there are screens for the different issue types which can be either for an individual project or shared across many projects. There are three screens for each issue type:
- A view screen
- A creation screen
- An update screen
For the view screen, it’s a good idea to include the Redmine issue ID. Likewise, the external issue should be excluded in the screens for updating and creating. The component and fix version attributes are already configured by default for the three screens.
Boards do not exist in Redmine, so for the different projects two boards were created: a scrum board and a Kanban board. The boards are configured to have a column for Undecided (needs more info), ToDo, In Progress, Verification, and Done. The administrator can change which issues are shown in the different columns. In addition, the administrator can add quick filters. We bootstrapped a few quick filters to include issues for the different team members, and also for components because Jira does not list the components on the left side of the backlog. There’s a tab for epics and versions, so it’s easy to filter on those values and move issues into a sprint. Components should have been an option below epics, where the marker is.
3. Problems with out of the box? Here’s how we did it.
We migrated using the importer plugins, but regardless of the method there are always things you need to consider.
What type of data do you want to import?
The REST API does not offer editing of all the data in Jira. As an example, the completion date of a sprint cannot be set using the REST API, so the statistics of a sprint will be gone. However, this is possible using the ScriptRunner extension. If you do not have that extension in your system, you’ll need to make do.
Comments may be imported without the correct user
When importing with the plugin tool users from the affected projects will be imported. If a user wrote a comment Jira will map that correctly, but if a user is not imported due to some problem (likely because the user has been deactivated), the comment will be created with the author being the person running the importer from inside Jira. In those cases, ScriptRunner came in handy to delete and re-create the comment with the correct author.
If ScriptRunner is not available it is possible to run the importer again after having deleted the issues where the author of the comment is the person who ran the importer. The user needs to be created manually in Jira with the same user name before running the importer again. Please remember that the user should be inactive and a bogus email can be used. The importer uses the external issue ID to determine which issues were already imported. The custom field can not be renamed during migration because a new custom field will be created, and all issues will be imported, essentially duplicating all the information.
The importer plugin bugs
In Jira, when subtasks have logged work, the parent story will aggregate those values so it’s easy to see how much time was spent in total. The problem was that the importer did not make the right links from the sub-tasks, messing up the time spent calculations.
To solve this problem we wrote a small Python script that outputted JSON to import the links correctly. The Python script is shown above. This Python function loads the relations of all types from a Redmine issue, e.g., copied_to which is identical to Jira’s cloners or duplicate relations.
Redmine REST API limitations
Redmine does not expose the dates and open/closed status of a release through the REST API. The dates were only available through web pages. Also, we wrote a small Python script to extract the dates from the HTML pages, so they could be set with the REST API.
The importer plugins do not behave optimally.
We have experienced some issues with the importer plugins which are highlighted in the above text. For most of the affected teams, the goal was to be able to work in Jira, so historic data could be presented slightly differently than in the tool migrated from.
Writing scripts to extract data from Jira 8.4 (and also for Jira 7) and onwards is a good investment because it’s easier to control how data is imported. Redmine does not have the notion of creator and reporter like Jira does. Ideally, all of the imported tickets should have the same values for creator and reporter. However, the importer sets the creator to the person who runs the importer. This may have the advantage that it’s easy to identify that those tickets came from a third-party system.
Resolution dates of imported issues
ScriptRunner also includes some functions, e.g., one that corrects the resolution status of a task. However, it does not preserve the resolution date and only caters for the bulk operation of more than a 1000 issues at once. The resolution date is needed for various statistics and charts. The 1000 issues limit is enforced by Atlassian when doing bulk editing through the interface. The resolution date problem from the built-in script can be solved by writing a custom script and we have one in our code-utils repository.
Many external issue ID custom fields
When importing many individual projects one external issue ID custom field will be created for each of the imported projects. We were not fully aware of this behavior until a few projects had been imported and created. The problem with multiple external issue ID custom fields is that links between issues in different projects will not be created.
One possible solution to this is to use an intermediary project to import (possibly in chunks) all the issues from Redmine and then bulk move them into new projects. This solution should be feasible with either method of importing the issues.
Then, when everything has been imported into Jira, you can use the script as described above to create the links between issues from different projects. It will not matter that some of the links already exist.
4. End result and reflections.
Workflow changes
If it’s the case that some old projects are being imported into an existing instance of Jira, it may be a good idea to evaluate how the two tools were used. Jira uses workflow to dictate how issues can be transitioned, and whether there are constraints on an issue going through all the different stages before it can be closed.
ScriptRunner
As described above, ScriptRunner can help you to adjust the data after the import to Jira. It was initially just requested to do post-processing of the imported data, but it proved useful to set conditions and post-functions in the workflows for the transitions. Conditions and validators can be used to guard against the same states, e.g., closed stories with open sub-tasks, which is one of the bundled scripts that ScriptRunner offers. There are some functions available that could be used as post-functions, e.g., closing the parent story when all sub-tasks have been closed. Since ScriptRunner exposes the entire internal plugin API of Jira and not only the REST API, it’s possible to write functions that do exactly what you need for your way of working.
Consider investing in ScriptRunner
Before starting a migration from a third-party tool it’s advisable to consider purchasing the ScriptRunner extension as it exposes all of Jira’s API through a console. The REST API has certain limitations, e.g., with sprints where not all metadata can be edited. It is very powerful to do post-processing of the imported data. The web is full of snippets that can be edited and adapted if you have some programming experience. The console offers auto-completion of the code. The ScriptRunner snippets that we used in the workflow and in the post-processing are open-source and available from the Praqma code-utils repository. The following snippet can be used as a condition on the resolve transition to guard against closing stories with open sub-tasks. Adaptavist has a nice tutorial on how to write custom conditions for a transition.
import com.atlassian.jira.issue.*;
import com.atlassian.jira.component.ComponentAccessor;
import com.atlassian.jira.issue.link.*;
import java.util.List
def issueLinkManager = ComponentAccessor.getIssueLinkManager()
def issueManager = ComponentAccessor.getIssueManager()
// issue is a special variable of the context of the transition
def issue = issue
// https://scriptrunner.adaptavist.com/latest/jira/custom-workflow-functions.html, see under Conditions
passesCondition = true
if(issue.getIssueType().getName() == "Story"){
List links = issueLinkManager.getInwardLinks(issue.id)
for(IssueLink issueLink : links){
if(issueLink.issueLinkType.name == "Is blocked by"){
def status = issueLink.destinationObject.getStatus().getName()
if(!["Rejected", "Done"].contains(status)){
passesCondition = false
break;
}
}
}
}
// functional programming style, no need for return
passesCondition
Even if you don’t plan to use the script console on more than a few occasions there are some JQL functions that can be used when searching for issues, and it can also be used to create new custom JQL functions.
Conclusion
In the migration process we ended up simplifying existing workflows so all teams were using the same workflow.
The teams started to fully embrace Atlassian’s Scrum features such as epics, and sprints in the Scrum methodology as supported by Jira.
If we were to do it again the importer plugins would be considered more carefully. They do a decent job but require time for writing scripts that verify that the data is actually imported correctly. However, they can leave some clean-up tasks behind that can be avoided by investing more time in writing scripts that do the extraction and adaptation of the data. The documentation describes exactly how the fields will be mapped when you use the importer.
The original number scheme (external issue ID) is of importance, for a few reasons. It ensures that importing the same issue twice is not possible, and it serves as a link between Jira and Redmine. By only having one external issue ID custom field, it’s also possible to maintain the links between issues in different projects.
ScriptRunner proved quite useful for both cleaning up and for the bundled JQL functions that can be used for queries for the boards, and when searching for issues. In addition, we have used it for workflow changes.
Published:
Updated:
